시나리오
새벽 3시 15분, 온콜 알람이 울립니다. Slack에는 "사이트 안 열려요"가 쌓이고 노트북을 열었는데 무엇부터 봐야 할지 막막합니다. 직감으로 "아마 앱 버그겠지"라며 kill -9부터 치면 증거는 사라지고 30분 뒤 같은 장애가 반복됩니다. 트리아지는 가장 낮은 계층(IP 연결)부터 올라가며 가설을 좁히는 것입니다 — 그 첫 5분이 사후 원인 분석 전체를 결정합니다.
서버 장애 초동 대응 — 5분 트리아지
이번 챕터에서 배울 것
1장애 계층(L3 IP → L4 포트 → L7 앱) 순서에 따라 원인을 좁혀갈 수 있다
2ping → ss → curl → journalctl → strace 5단계를 손에 익혀 실행할 수 있다
3죽이기 전에 strace·코어덤프·로그로 증거를 수집하는 원칙을 적용할 수 있다
4CPU·메모리·디스크·네트워크를 1분 안에 한 화면으로 진단할 수 있다
5script 명령으로 장애 대응 세션 전체를 기록하고 팀에 공유할 수 있다
실습 환경 준비
실습 환경 확인
uname -r && lsb_release -d
ss 도구 확인 (iproute2 패키지)
ss --version
script 도구 확인 (util-linux 기본 포함)
which script
strace 설치 확인 (없으면 설치)
which strace || sudo apt install strace -y
— — —
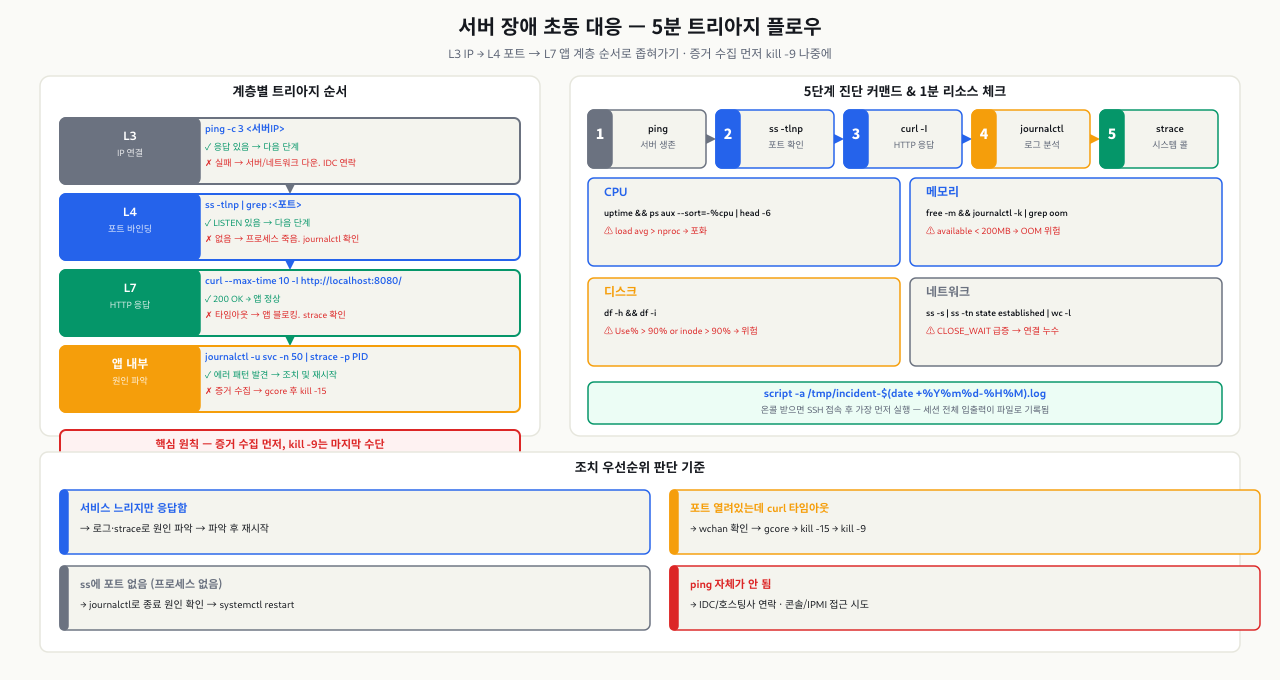
장애를 진단할 때 가장 흔한 실수는 "아마 앱 문제겠지"라며 L7(애플리케이션)부터 보는 것입니다. 그러나 L3(IP) 연결 자체가 끊어진 상황에서 로그를 아무리 뒤져도 원인을 찾을 수 없습니다. 반대로 L3가 정상이면 L4(포트)를, L4가 정상이면 L7(앱)을 보는 순서가 문제를 가장 빠르게 좁혀줍니다.
장애 계층을 아래에서 위로 확인합니다.
| 계층 |
질문 |
도구 |
| L3 — IP 연결 |
서버에 네트워크로 닿는가? |
ping, ip addr |
| L4 — 포트 바인딩 |
서비스가 포트에 LISTEN하고 있는가? |
ss -tlnp |
| L7 — 앱 응답 |
포트에 요청했을 때 정상 응답이 오는가? |
curl -v, curl -I |
| 앱 내부 |
앱이 무엇을 하고 있는가? (느리다, 멈췄다) |
journalctl, strace |
계층 진단의 실용적 의미:
ping이 실패한다 → 서버 자체가 죽었거나 네트워크 단절. 이 상황에서 앱 로그를 볼 방법이 없습니다. IDC 담당자에게 연락하거나 콘솔 접근을 시도합니다.ping은 되는데 ss에 포트가 없다 → 프로세스가 죽었거나 시작 실패. journalctl로 이유를 확인합니다.ss에 포트는 있는데 curl이 실패한다 → 방화벽 차단이거나 앱이 요청을 처리하지 못하는 상태. curl -v로 TLS, 리디렉션 등을 추적합니다.curl은 200인데 사용자가 이상하다 한다 → 특정 엔드포인트, 캐시, CDN, 특정 사용자 데이터 문제. L7 이상의 비즈니스 로직 레벨입니다.
이 순서를 따르면 "어디서부터 볼지 모른다"는 상황이 사라집니다.
— — —
실습 1 — 5단계 확인 순서
아래 순서는 서비스 장애 시 손에 익어야 할 기본 진단 흐름입니다. 실제 장애 상황을 가정하고 각 단계를 순서대로 실행해 봅니다.
단계 1: ping — 서버가 살아있는가?
bash# 서버 자체 응답 확인 (외부에서 접근하는 상황을 가정)
ping -c 3 <서버_IP>
# 예시 출력 (정상)
# PING 10.0.1.5 (10.0.1.5) 56(84) bytes of data.
# 64 bytes from 10.0.1.5: icmp_seq=1 ttl=64 time=0.412 ms
# 64 bytes from 10.0.1.5: icmp_seq=2 ttl=64 time=0.398 ms
# 64 bytes from 10.0.1.5: icmp_seq=3 ttl=64 time=0.421 ms
# --- 10.0.1.5 ping statistics ---
# 3 packets transmitted, 3 received, 0% packet loss
# 로컬 루프백 확인 (서버 내부에서)
ping -c 2 127.0.0.1
단계 2: ss — 포트가 열려있는가?
bash# TCP LISTEN 포트와 프로세스 전체 목록
ss -tlnp
# 예시 출력
# State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
# LISTEN 0 128 0.0.0.0:22 0.0.0.0:* users:(("sshd",pid=1023,fd=3))
# LISTEN 0 511 0.0.0.0:80 0.0.0.0:* users:(("nginx",pid=2341,fd=6))
# LISTEN 0 128 127.0.0.1:8080 0.0.0.0:* users:(("node",pid=3102,fd=18))
# 특정 포트만 확인 (예: 8080)
ss -tlnp | grep :8080
# 출력이 없다면 → 8080 포트를 LISTEN하는 프로세스가 없다 → 프로세스 문제
단계 3: curl — 앱이 응답하는가?
bash# HTTP 상태코드와 응답 헤더 확인
curl -I http://localhost:8080/
# 예시 출력 (정상)
# HTTP/1.1 200 OK
# Server: nginx/1.24.0 (Ubuntu)
# Date: Sun, 10 May 2026 03:15:42 GMT
# Content-Type: text/html; charset=UTF-8
# Connection: keep-alive
# 응답 내용 포함, 리디렉션까지 추적
curl -Lv http://localhost:8080/ 2>&1 | head -30
# 타임아웃 설정 (응답이 없을 때 무한 대기 방지)
curl --connect-timeout 5 --max-time 10 -o /dev/null -w "%{http_code}" http://localhost:8080/
단계 4: journalctl — 로그가 무슨 말을 하는가?
bash# 특정 서비스의 최근 50줄 로그
journalctl -u nginx -n 50 --no-pager
# 최근 10분간 로그 (장애 시각을 특정할 수 있을 때)
journalctl -u nginx --since "10 minutes ago" --no-pager
# 커널 메시지 포함 전체 시스템 로그 (OOM, 디스크 오류 등)
journalctl -k --since "30 minutes ago" --no-pager | grep -E "error|fail|warn|oom|kill" -i
# 실시간 로그 추적 (터미널 하나 더 열어서)
journalctl -u nginx -f
단계 5: strace — 프로세스가 지금 무엇을 하는가?
bash# 프로세스 PID 확인
ss -tlnp | grep :8080
# 또는
pgrep -a node
# strace로 시스템 콜 추적 (I/O 대기, 네트워크 호출 등)
# -p: 실행 중인 프로세스에 붙기
# -e: 특정 시스템 콜만 필터
# -T: 각 시스템 콜 소요 시간 표시
sudo strace -p -e trace=network,read,write -T 2>&1 | head -30
# 예시 출력 (파일 I/O에서 멈춰있는 상황)
# read(7, 0x7f3a1c002e00, 4096) = ? ERESTARTSYS (To be restarted if SA_RESTART is set) <30.123456>
# — 30초째 read 시스템 콜에 멈춰있음 → NFS 마운트 문제나 디스크 행일 가능성
# 프로세스가 무엇에 멈춰있는지 빠르게 보기
sudo cat /proc//wchan
# 출력 예: ep_poll → epoll 대기 (정상), read_wait → 읽기 대기 (디스크 문제 의심)
— — —
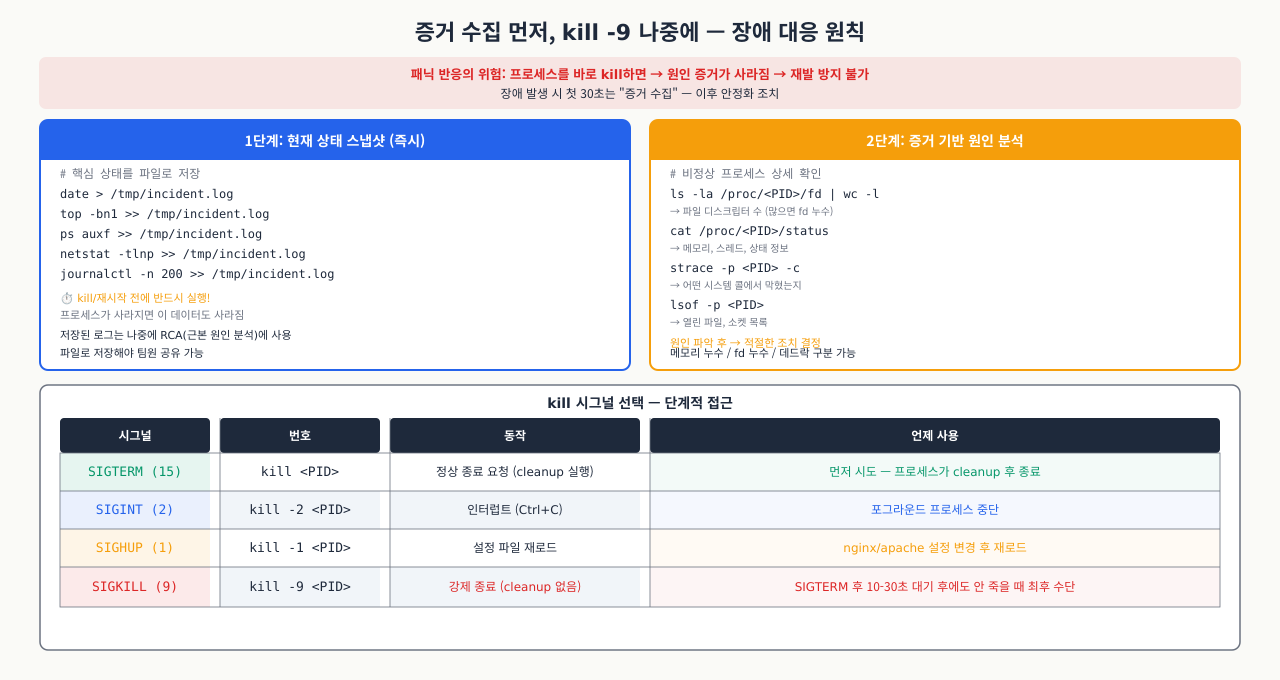
새벽 3시에 서비스가 멈췄을 때 가장 빠른 해결책은 kill -9처럼 보입니다. 실제로 프로세스를 죽이고 재시작하면 서비스는 살아납니다. 하지만 5분 뒤, 혹은 다음 날 같은 장애가 반복될 때 원인을 찾을 방법이 없습니다. SIGKILL은 커널이 프로세스를 즉시 제거하기 때문에 스택 트레이스, 최근 메모리 상태, 열린 파일 목록, 코어 덤프가 모두 사라집니다.
증거를 수집하는 것이 왜 중요한가:
bash# 죽이기 전에 이것들을 먼저 확보합니다
# 1. 프로세스가 열고 있는 파일 목록 (fd 고갈 여부 확인)
ls -la /proc/<PID>/fd | wc -l
ls -la /proc/<PID>/fd | tail -10
# 2. 현재 메모리 맵 (메모리 누수 확인)
cat /proc/<PID>/smaps_rollup
# 3. 최근 시스템 콜 기록 (strace로 마지막 행동 확인)
sudo strace -p <PID> -c -f -T -- sleep 5 2>&1
# 4. 코어 덤프 활성화 (크래시 직전 상태 보존)
# 코어 덤프를 /tmp에 저장하도록 설정
echo '/tmp/core-%e-%p' | sudo tee /proc/sys/kernel/core_pattern
ulimit -c unlimited
# 5. 그 다음에 SIGTERM으로 정상 종료 요청
sudo kill -15 <PID>
# 10초 기다려도 안 죽으면 그때 kill -9
sleep 10 && sudo kill -9 <PID>
실무 원칙:
| 상황 |
행동 |
| 서비스가 느리지만 응답함 |
로그, strace로 원인 파악 → 파악 후 재시작 |
| 서비스가 전혀 응답 안 함 (포트는 열림) |
증거 수집 → SIGTERM → 10초 대기 → SIGKILL |
| 서비스 프로세스가 없음 (포트 없음) |
journalctl로 종료 원인 확인 → 재시작 |
| 서버 자체가 응답 없음 |
콘솔/IPMI 접근, 호스팅사 연락 — 원격 로그 확인 불가 |
— — —
실습 2 — CPU/메모리/디스크/네트워크 1분 진단
장애 상황에서 리소스 고갈이 원인인 경우가 많습니다. 아래 커맨드 세트를 한 화면에서 순서대로 실행하면 1분 안에 리소스 상태를 파악할 수 있습니다.
CPU 진단
bash# 로드 평균과 CPU 상태 (1분/5분/15분 평균)
uptime
# 예시 출력:
# 03:18:42 up 12 days, 4:32, 2 users, load average: 8.21, 6.45, 4.12
# 코어 수 확인 — load average가 코어 수보다 크면 포화 상태
nproc
# CPU를 가장 많이 쓰는 프로세스 상위 10개
ps aux --sort=-%cpu | head -11
# 실시간 확인 (3초 갱신, 3회 후 종료)
top -b -n 3 -d 3 | grep -A 15 "PID USER"
메모리 진단
bash# 전체 메모리 현황 (MB 단위)
free -m
# 예시 출력:
# total used free shared buff/cache available
# Mem: 15872 9823 412 215 5637 5603
# Swap: 2047 1234 813
# available이 매우 낮으면 OOM 위험
# 메모리를 가장 많이 쓰는 프로세스 상위 10개
ps aux --sort=-%mem | head -11
# OOM Killer 발생 이력 확인 (최근 장애 원인)
sudo journalctl -k | grep -i "oom\|out of memory\|killed process" | tail -20
디스크 진단
bash# 마운트된 파일시스템 사용률
df -h
# 예시 출력 (위험 상황):
# Filesystem Size Used Avail Use% Mounted on
# /dev/sda1 50G 48G 234M 99% /
# /dev/sdb1 200G 12G 188G 6% /data
# inode 고갈 확인 (파일 수 부족으로 디스크 full처럼 동작하는 경우)
df -i | grep -v tmpfs
# 디스크 I/O 대기 확인
iostat -x 1 3 2>/dev/null || sar -d 1 3 2>/dev/null || cat /proc/diskstats | head -5
# 큰 파일/디렉토리 찾기 (디스크 가득 찼을 때)
du -sh /var/log/* 2>/dev/null | sort -rh | head -10
네트워크 진단
bash# 현재 연결 상태 요약
ss -s
# 예시 출력:
# Total: 1234
# TCP: 856 (estab 820, closed 12, orphaned 0, timewait 24)
# 대량의 TIME_WAIT나 CLOSE_WAIT는 연결 누수 의심
# 연결이 많은 IP 상위 10개 (DDoS, 크롤러 의심)
ss -tn state established | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -rn | head -10
# 네트워크 인터페이스 오류 카운터 확인
ip -s link show | grep -A 5 "eth\|ens\|enp" | grep -E "RX|TX|errors"
— — —
개념
script 명령으로 장애 대응 세션 기록

장애 대응 중 어떤 명령을 어떤 순서로 실행했는지 나중에 재구성하는 것은 매우 어렵습니다. bash_history는 타임스탬프가 없고, 여러 터미널에서 작업하면 순서도 뒤섞입니다. script 명령은 터미널 세션 전체(입력과 출력 모두)를 파일로 기록합니다. 장애가 끝난 뒤 팀에 공유하거나 포스트모텀을 작성할 때 결정적인 자료가 됩니다.
bash# 장애 대응 시작 전 — 세션 기록 시작
script -a -t 2>/tmp/incident-$(date +%Y%m%d-%H%M).timing /tmp/incident-$(date +%Y%m%d-%H%M).log
# -a: 기존 파일이 있으면 덧붙이기
# -t: 타임스탬프 파일 생성 (재생 속도 정보)
# 이제부터 이 터미널에서 실행하는 모든 명령과 출력이 기록됩니다
# 평소처럼 진단 명령을 실행합니다
ping -c 3 10.0.1.5
ss -tlnp
journalctl -u myapp -n 50 --no-pager
# 기록 종료
exit
# 또는 Ctrl+D
# 기록된 파일 확인
ls -lh /tmp/incident-*
# -rw-r--r-- 1 ubuntu ubuntu 24K May 10 03:42 /tmp/incident-20260510-0315.log
# -rw-r--r-- 1 ubuntu ubuntu 4.8K May 10 03:42 /tmp/incident-20260510-0315.timing
# 세션 재생 (정확한 타임라인 확인)
scriptreplay -t /tmp/incident-20260510-0315.timing /tmp/incident-20260510-0315.log
# 팀 공유용 — 읽기 쉬운 텍스트만 Slack에 첨부
cat /tmp/incident-20260510-0315.log
실무 팁 — 장애 대응 시작 루틴:
bash# ~/.bashrc 또는 ~/.bash_profile에 추가해두면 편합니다
alias incident='script -a -t 2>/tmp/incident-$(date +%Y%m%d-%H%M).timing /tmp/incident-$(date +%Y%m%d-%H%M).log && echo "Recording started. Type exit to stop."'
온콜을 받으면 SSH 접속 후 incident를 먼저 입력하는 것을 습관으로 만들면, 나중에 "그때 뭘 했더라"를 고민할 필요가 없어집니다.
— — —
트러블슈팅
서비스 응답 없음 — 그런데 프로세스는 살아있음 (포트도 열려있음)
상황: 사용자들이 "사이트 안 열린다"고 하는데, ss -tlnp에는 포트가 정상 표시되고, ps aux에도 프로세스가 살아있습니다. systemctl status는 active (running)입니다.
bash# 확인 1: ss에 포트가 있는지
ss -tlnp | grep :8080
# LISTEN 0 511 0.0.0.0:8080 0.0.0.0:* users:(("node",pid=4201,fd=18))
# → 포트 있음
# 확인 2: curl로 실제 응답 확인
curl --connect-timeout 5 --max-time 15 -o /dev/null -w "%{http_code}\n" http://localhost:8080/
# → (30초 뒤) 000
# → 연결은 됐지만 응답을 안 줌
원인: 프로세스가 TCP 연결은 수락하지만 실제 요청을 처리하지 못하는 상태입니다. 흔한 원인은 세 가지입니다.
- 데드락(deadlock) — 스레드가 서로의 락을 기다리며 멈춤
- 이벤트 루프 차단 — Node.js 같은 싱글스레드 앱에서 동기 블로킹 연산이 루프를 점령
- 외부 의존성 대기 — DB 연결 풀 고갈, Redis 타임아웃 등으로 모든 스레드가 대기 중
진단
bash# 프로세스가 무엇을 기다리는지 확인
sudo cat /proc/4201/wchan
# 출력 예: futex_wait_queue → 락 대기 (데드락 의심)
# 출력 예: ep_poll → epoll 대기 (정상적인 이벤트 대기)
# 열린 파일 디스크립터 수 확인 (fd 고갈 여부)
ls /proc/4201/fd | wc -l
# 1024 이상이면 fd 고갈 근처 (기본 ulimit -n은 1024)
cat /proc/4201/limits | grep "open files"
# 스레드별 상태 확인 (Java, Go 등 멀티스레드 앱)
ls /proc/4201/task/ # 스레드 목록
# 각 스레드의 wchan 확인
for tid in $(ls /proc/4201/task/); do
echo -n "Thread $tid: "
cat /proc/4201/task/$tid/wchan 2>/dev/null
done
# 시스템 콜 추적으로 실제 행동 파악
sudo strace -p 4201 -e trace=network,futex -T 2>&1 | head -20
# futex(0x..., FUTEX_WAIT, ...) = ? ERESTARTSYS ... <120.456789>
# → 120초째 futex 대기 → 데드락 확정
# DB 연결 상태 확인 (PostgreSQL 예시)
ss -tn state established dst :5432 | wc -l
# 연결 풀 크기(예: 10)보다 훨씬 많으면 → 연결 풀 고갈
해결
bash# 1. 증거 수집 (kill 전에 반드시)
sudo gcore 4201 # 코어 덤프 생성 (/core.4201 로 저장)
# 또는 Java라면
sudo kill -3 4201 # Thread dump를 stdout/stderr에 출력
# 2. SIGTERM으로 정상 종료 시도
sudo kill -15 4201
sleep 10
# 3. 안 죽으면 SIGKILL
sudo kill -9 4201
# 4. 재시작
sudo systemctl restart myapp
# 5. 재발 방지 — 앱 레벨 타임아웃 설정 검토
# DB 연결 풀 타임아웃, HTTP 요청 타임아웃 등
— — —
실무 맥락
SRE 온콜 첫 5분 — script 기록 시작 후 L3·L4·L7 계층 순서로 증거 수집하며 원인 좁히기
실제 SRE 엔지니어가 온콜을 받았을 때의 첫 5분을 재현합니다. 순서가 중요합니다.
0분: 알람 수신
bash# SSH 접속 후 가장 먼저 세션 기록 시작
script -a /tmp/incident-$(date +%Y%m%d-%H%M).log
# 알람 발생 시각 기준 최근 로그부터 확인
echo "=== Triage Start: $(date) ===" | tee -a /tmp/incident-notes.txt
1분: 서버 생존 확인 + 기초 자원
bash# 한 줄로 핵심 지표 확인
uptime && free -m | awk '/Mem/{printf "Mem: %dMB used / %dMB total\n", $3, $2}' && df -h / | awk 'NR==2{print "Disk:", $5, "used"}'
# 예시 출력:
# 03:18:00 up 45 days, 2:31, 1 user, load average: 12.5, 8.3, 5.1
# Mem: 14500MB used / 15872MB total
# Disk: 87% used
# → load average 12.5, 코어 4개 → CPU 포화. 메모리도 빡빡. 디스크 87%
2분: 포트 및 프로세스 상태
bash# 서비스 관련 포트 확인
ss -tlnp | grep -E ":80|:443|:8080|:3000|:5432|:6379"
# 비정상 CPU 사용 프로세스
ps aux --sort=-%cpu | head -6
# 최근 죽은 프로세스 (OOM, 크래시)
sudo journalctl -k --since "15 minutes ago" | grep -E "killed|oom|segfault"
3분: 앱 레벨 응답 확인
bash# 주요 엔드포인트 응답 코드 확인
for url in http://localhost:80/ http://localhost:8080/health; do
code=$(curl --connect-timeout 3 --max-time 8 -o /dev/null -s -w "%{http_code}" "$url" 2>/dev/null || echo "ERR")
echo "$url → $code"
done
# 서비스 로그 최근 에러
sudo journalctl -u myapp --since "10 minutes ago" --no-pager | grep -i "error\|fatal\|panic" | tail -20
4분: 원인 가설 수립
지금까지 수집한 데이터를 바탕으로 가설을 메모합니다.
bash# 조사 결과를 노트 파일에 기록
cat >> /tmp/incident-notes.txt << 'EOF'
[03:19] 증상:
- load average 12.5 (코어 4) → CPU 포화
- 포트 8080 LISTEN 있음
- curl localhost:8080/health → 000 (타임아웃)
- journalctl: "FATAL: too many connections" (03:14)
가설:
- DB 연결 풀 고갈 → 모든 요청 대기 → 이벤트 루프 포화
- 확인 필요: DB 연결 수, 슬로우 쿼리
EOF
5분: 조치 또는 에스컬레이션
원인이 파악됐으면 조치하고, 파악이 안 됐으면 팀 채널에 지금까지 수집한 내용을 공유하고 에스컬레이션합니다. 추측으로 kill -9를 치는 것은 마지막 수단입니다.
bash# 조치 후 서비스 재기동
sudo systemctl restart myapp
# 재기동 후 상태 확인
sleep 5 && curl --max-time 5 -o /dev/null -s -w "%{http_code}" http://localhost:8080/health
# 세션 기록 종료
exit
# 팀 채널에 incident log 첨부
# cat /tmp/incident-20260510-0315.log | head -100
다음 모듈에서는 방화벽 — firewalld와 iptables로 인바운드/아웃바운드 트래픽을 제어하고, 포트 차단으로 인한 접속 불가 문제를 진단하는 방법을 다룹니다.