배포한 서버에 갑자기 접속이 안 됩니다. 로그를 봐도 애플리케이션은 정상입니다. "어디서부터 확인해야 하나." IP가 잘못 설정된 건지, 포트가 닫힌 건지, DNS 문제인지 — 체계 없이 방화벽만 한참 뒤지다 결국 DNS 설정 오류였다는 결론에 도달하기도 합니다.
OSI 계층 순서대로 ping → ss → dig → curl을 돌리면 대부분의 네트워크 장애를 스스로 추적할 수 있습니다.
네트워킹 기초 (Networking Basics)
which ip ss tcpdump curl dig || sudo apt-get install -y iproute2 tcpdump curl dnsutils
ip -br addr show
ip route show

curl로 외부 API를 호출하는데 응답이 없을 때, DNS 문제인지 라우팅 문제인지 방화벽 문제인지 바로 알기 어렵습니다. 체계 없이 접근하면 방화벽만 한참 뒤지다 결국 DNS 설정 오류였다는 결론에 도달하기도 합니다. OSI 7계층 모델을 리눅스 명령어와 연결해두면, 계층별로 "여기까지는 되고 여기서부터 안 된다"는 방식으로 원인을 좁힐 수 있습니다.
네트워크 문제를 진단할 때 어느 계층의 문제인지 빠르게 파악하는 것이 핵심입니다. OSI 7계층 모델을 Linux 명령어와 매핑하면 다음과 같습니다.
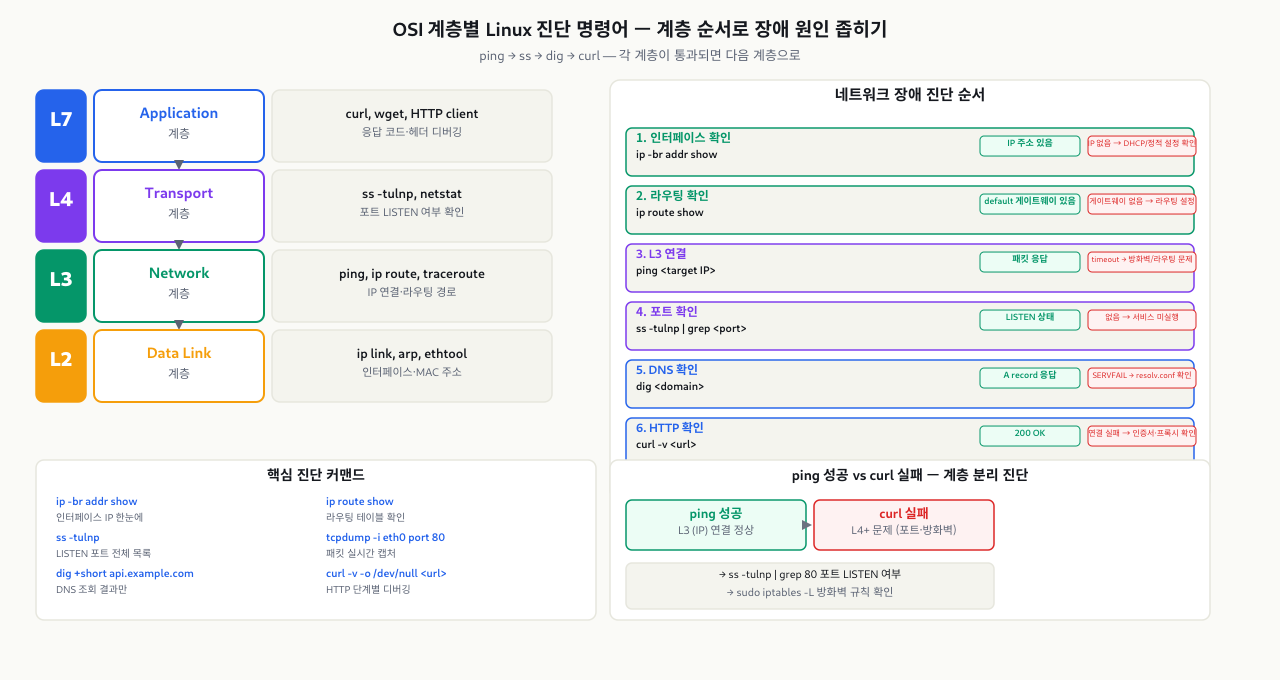
| 계층 | 이름 | 역할 | Linux 도구 |
|---|---|---|---|
| L7 | 응용 계층 | HTTP, DNS, SSH 프로토콜 | curl, dig, ssh |
| L4 | 전송 계층 | TCP/UDP 포트, 연결 상태 | ss, netstat, tcpdump |
| L3 | 네트워크 계층 | IP 라우팅, ICMP | ip route, ping, traceroute, mtr |
| L2 | 데이터링크 계층 | MAC 주소, 이더넷 프레임 | ip link, arp |
트러블슈팅 원칙: L2 → L3 → L4 → L7 순서로 아래에서 위로 확인합니다.
- 인터페이스가 UP인가? (L2)
- IP가 올바르고 라우팅이 되는가? (L3)
- 포트가 열려 있는가? (L4)
- 애플리케이션이 올바르게 응답하는가? (L7)
주의: ifconfig와 netstat은 net-tools 패키지에 포함된 구버전 도구입니다. 현대 Linux에서는 ip 명령어(iproute2 패키지)와 ss로 대체되었습니다. 일부 배포판에서는 기본 설치되어 있지 않습니다.

검색해서 나온 네트워크 설정 가이드가 ifconfig eth0 192.168.1.10으로 시작하는데, 그 명령이 서버에 없어서 당황한 경험이 있을 것입니다. Ubuntu 18.04부터 net-tools 패키지(ifconfig, netstat, route 포함)가 기본 설치에서 빠졌습니다. 현대 Linux에서는 ip 명령어 하나로 인터페이스 조회, IP 설정, 라우팅 관리를 모두 처리합니다. 구글에서 나온 오래된 예제와 현재 시스템 명령어가 다른 이유가 이 deprecated 때문이므로, 어떻게 대응하는지 한 번 익혀두면 혼란이 사라집니다.
ip 명령어는 iproute2 패키지의 핵심으로, 네트워크 인터페이스·라우팅·터널·정책 라우팅을 통합적으로 다룹니다.
기본 구조 — ip [옵션] <오브젝트> <커맨드> 형식으로 네트워크 오브젝트를 제어합니다:
ip [옵션] <오브젝트> <커맨드>
주요 오브젝트:
| 오브젝트 | 줄임 | 역할 |
|---|---|---|
address |
addr, a |
IP 주소 관리 |
link |
l |
네트워크 인터페이스(L2) 상태 |
route |
r |
라우팅 테이블 |
neighbour |
neigh |
ARP 테이블 |
ifconfig vs ip 대응표 — 구버전 ifconfig 명령을 현대적인 ip 명령으로 대체하는 치환 목록입니다:
| 구버전 (ifconfig) | 신버전 (ip) |
|---|---|
ifconfig |
ip addr show |
ifconfig eth0 up |
ip link set eth0 up |
ifconfig eth0 192.168.1.10/24 |
ip addr add 192.168.1.10/24 dev eth0 |
route -n |
ip route show |
route add default gw 192.168.1.1 |
ip route add default via 192.168.1.1 |
출력을 사람이 읽기 좋게 만들려면 -c 플래그로 컬러 출력을, -br 플래그로 간결한 브리프 형식을 사용합니다:
baship -c -br addr show
실습 전 디렉토리와 예제 파일을 먼저 준비합니다.
bash# 실습 디렉토리 준비 mkdir -p /tmp/linux/part4/exam_1 && cd /tmp/linux/part4/exam_1
이제 실습을 진행합니다.
현재 시스템의 모든 네트워크 인터페이스와 IP 주소를 확인합니다.
bash# 모든 인터페이스 표시 ip addr show # 특정 인터페이스만 ip addr show eth0 # 간결한 형식 (브리프) ip -br addr show
출력 예시 — ip addr show의 실제 출력에서 각 줄이 의미하는 것을 확인합니다:
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo inet6 ::1/128 scope host 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000 link/ether 52:54:00:ab:cd:ef brd ff:ff:ff:ff:ff:ff inet 10.0.1.15/24 brd 10.0.1.255 scope global eth0 inet6 fe80::5054:ff:feab:cdef/64 scope link
읽는 법:
UP,LOWER_UP— 인터페이스가 활성화되어 물리 링크도 연결됨inet 10.0.1.15/24— IPv4 주소와 서브넷 마스크mtu 1500— 최대 전송 단위 (바이트). 점보 프레임은 9000scope global— 외부 통신 가능한 주소 (host는 루프백 전용)
인터페이스 상태만 빠르게 확인 — UP/DOWN 상태와 IP 주소를 한 줄로 빠르게 확인합니다:
baship link show # 또는 ip -br link show
lo UNKNOWN 00:00:00:00:00:00 <LOOPBACK,UP,LOWER_UP> eth0 UP 52:54:00:ab:cd:ef <BROADCAST,MULTICAST,UP,LOWER_UP> docker0 DOWN 02:42:a3:1b:2c:4d <NO-CARRIER,BROADCAST,MULTICAST,UP>
baship addr show
ss(socket statistics)는 netstat의 현대적 대체 도구입니다. 커널 직접 조회로 netstat보다 빠릅니다.
bash# TCP 리스닝 포트와 프로세스 표시 ss -tlnp # UDP 리스닝 소켓 ss -ulnp # TCP/UDP 모두, ESTABLISHED 포함 ss -anp # 특정 포트 필터 ss -tlnp sport = :8080 # 특정 프로세스 ID로 필터 ss -tlnp | grep pid=1234
주요 플래그 — -t, -u, -l, -n, -p 각 플래그의 의미입니다:
| 플래그 | 의미 |
|---|---|
-t |
TCP 소켓만 |
-u |
UDP 소켓만 |
-l |
LISTEN 상태만 |
-n |
포트를 숫자로 (이름 해석 안 함, 빠름) |
-p |
프로세스 정보 표시 (root 권한 필요) |
-a |
모든 상태 (LISTEN + ESTABLISHED 등) |
출력 예시 — ss -tulnp 실제 출력에서 각 컬럼이 의미하는 정보입니다:
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process LISTEN 0 128 0.0.0.0:22 0.0.0.0:* users:(("sshd",pid=987,fd=3)) LISTEN 0 511 0.0.0.0:80 0.0.0.0:* users:(("nginx",pid=1234,fd=6)) LISTEN 0 128 127.0.0.1:5432 0.0.0.0:* users:(("postgres",pid=2345,fd=5)) LISTEN 0 128 0.0.0.0:8080 0.0.0.0:* users:(("java",pid=3456,fd=12))
읽는 법:
0.0.0.0:80— 모든 인터페이스에서 수신 (외부 접근 가능)127.0.0.1:5432— 루프백만 수신 (로컬 전용, 외부 차단)Recv-Q— 수신 버퍼에 쌓인 바이트 (0이 정상; 높으면 애플리케이션이 처리 못 함)Send-Q— 송신 버퍼에 쌓인 바이트 (0이 정상; 높으면 네트워크 병목)
연결 상태별 요약 통계 — ss -s로 소켓 상태별 총 개수를 빠르게 파악합니다:
bashss -s
Total: 412 TCP: 87 (estab 43, closed 12, orphaned 0, timewait 32)
bashss -tlnp
패킷이 어떤 경로로 나가는지 확인합니다.
bash# 라우팅 테이블 전체 표시 ip route show # 특정 목적지로 가는 경로 조회 ip route get 8.8.8.8
출력 예시 — ip route show에서 기본 라우팅 테이블을 읽는 법입니다:
default via 10.0.1.1 dev eth0 proto dhcp src 10.0.1.15 metric 100 10.0.1.0/24 dev eth0 proto kernel scope link src 10.0.1.15 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
읽는 법:
default via 10.0.1.1— 기본 게이트웨이 (나머지 모든 트래픽 여기로)10.0.1.0/24 dev eth0 ... scope link— 같은 서브넷, 직접 연결metric 100— 경로 우선순위 (낮을수록 우선)
특정 IP로 가는 실제 경로 — ip route get으로 특정 목적지까지 실제로 어떤 경로를 쓰는지 확인합니다:
baship route get 8.8.8.8 # 8.8.8.8 via 10.0.1.1 dev eth0 src 10.0.1.15 uid 0
경로 추적 — traceroute / mtr — 목적지까지 각 홉을 추적해 어디서 지연이 발생하는지 파악합니다:
bash# 경로 추적 (각 홉의 지연) traceroute 8.8.8.8 # mtr: traceroute + ping 실시간 통합 (더 유용) mtr --report --report-cycles 10 8.8.8.8
Start: 2026-03-26T03:45:00+0000 HOST: web-server-01 Loss% Snt Last Avg Best Wrst StDev 1.|-- 10.0.1.1 0.0% 10 0.4 0.5 0.4 0.7 0.1 2.|-- 203.0.113.1 0.0% 10 1.2 1.3 1.1 1.6 0.2 3.|-- 8.8.8.8 0.0% 10 11.4 11.6 11.2 12.1 0.3
Loss%가 중간 홉에서만 높고 최종 목적지는 정상이면, 해당 홉이 ICMP를 rate-limit하는 것일 수 있습니다.
baship route show
tcpdump는 L3/L4 수준의 실제 패킷을 캡처해 분석합니다. root 또는 CAP_NET_RAW 권한이 필요합니다.
bash# 기본: eth0에서 포트 80 트래픽 캡처, 파일로 저장 sudo tcpdump -i eth0 port 80 -w /tmp/cap.pcap # 화면에서 실시간으로 읽기 (저장 안 함) sudo tcpdump -i eth0 port 80 -n # 저장된 파일 읽기 tcpdump -r /tmp/cap.pcap # 특정 호스트와의 트래픽만 sudo tcpdump -i eth0 host 10.0.1.20 -n # HTTP GET 요청만 (문자열 필터) sudo tcpdump -i eth0 -A -s0 port 80 | grep "GET\|POST\|HTTP" # SYN 패킷만 (연결 시도) sudo tcpdump -i eth0 'tcp[tcpflags] & tcp-syn != 0' -n
주요 플래그 — tcpdump 옵션의 의미입니다:
| 플래그 | 의미 |
|---|---|
-i eth0 |
인터페이스 지정 (-i any는 모든 인터페이스) |
-n |
IP/포트를 숫자로 (해석 안 함, 빠름) |
-v, -vv |
상세 출력 |
-A |
패킷 내용을 ASCII로 출력 |
-s0 |
패킷 전체 캡처 (기본은 일부만) |
-w file |
파일로 저장 (Wireshark에서 분석 가능) |
-c 100 |
100개 패킷 후 종료 |
실시간 출력 예시 — mtr이 각 홉의 지연시간과 패킷 손실률을 실시간으로 출력하는 형태입니다:
03:45:10.123456 IP 10.0.1.20.52341 > 10.0.1.15.80: Flags [S], seq 1234567890, win 64240 03:45:10.123789 IP 10.0.1.15.80 > 10.0.1.20.52341: Flags [S.], seq 987654321, ack 1234567891, win 65535 03:45:10.124012 IP 10.0.1.20.52341 > 10.0.1.15.80: Flags [.], ack 1, win 502
[S] = SYN, [S.] = SYN-ACK, [.] = ACK — TCP 3-way handshake가 정상임을 확인할 수 있습니다.
Wireshark로 심층 분석: .pcap 파일을 로컬로 복사해 Wireshark GUI에서 열면 스트림 재조립, HTTP 디코딩 등이 가능합니다.
bashscp server:/tmp/cap.pcap ~/Downloads/
bashtcpdump -i eth0 port 80 -w /tmp/cap.pcap
curl은 HTTP(S) 요청을 직접 보내 애플리케이션 계층(L7)을 검증하는 필수 도구입니다.
bash# 상세 출력 (TLS 핸드셰이크, 헤더, 응답 포함) curl -v https://example.com # 응답 헤더만 확인 (HEAD 요청) curl -I https://example.com # 응답 시간 측정 (성능 분석) curl -o /dev/null -s -w "DNS: %{time_namelookup}s\nTCP connect: %{time_connect}s\nTLS: %{time_appconnect}s\nFirst byte: %{time_starttransfer}s\nTotal: %{time_total}s\n" https://example.com # POST 요청 curl -X POST https://api.example.com/v1/items \ -H "Content-Type: application/json" \ -H "Authorization: Bearer $TOKEN" \ -d '{"name": "widget", "qty": 5}' # 특정 IP로 요청 (DNS 우회, 로드밸런서 뒤 특정 서버 테스트) curl -v --resolve example.com:443:10.0.1.15 https://example.com # 응답 코드만 확인 curl -o /dev/null -s -w "%{http_code}" https://example.com
`curl -v` 출력 읽는 법 — > 는 요청, < 는 응답 헤더를 나타내며 DNS→TCP→HTTP 단계를 추적합니다:
* Trying 93.184.216.34:443... ← TCP 연결 시도 * Connected to example.com port 443 ← TCP 연결 성공 * TLSv1.3, TLS handshake ← TLS 협상 시작 * SSL connection using TLSv1.3 ← TLS 연결 성공 > GET / HTTP/2 ← 요청 헤더 (> 는 송신) > Host: example.com > User-Agent: curl/8.4.0 > < HTTP/2 200 ← 응답 헤더 (< 는 수신) < content-type: text/html < content-length: 1256 < <!doctype html>... ← 응답 바디
응답 시간 분석 예시 — curl -w 포맷으로 각 단계별 소요 시간을 측정합니다:
DNS: 0.003s ← DNS 조회 (느리면 resolv.conf 확인) TCP connect: 0.012s ← TCP handshake (느리면 네트워크 레이턴시) TLS: 0.045s ← TLS 협상 (느리면 인증서 체인 문제) First byte: 0.234s ← 서버 처리 시간 (TTFB) Total: 0.891s ← 전체 소요 시간
bashcurl -v https://example.com
DNS 해석 실패의 대부분은 이 두 파일과 systemd-resolved 설정에서 비롯됩니다.
bash# DNS 서버 설정 확인 cat /etc/resolv.conf
# Generated by systemd-resolved nameserver 127.0.0.53 options edns0 trust-ad search example.internal
bash# 로컬 호스트 오버라이드 확인 cat /etc/hosts
127.0.0.1 localhost ::1 localhost ip6-localhost 10.0.1.100 db.internal postgres.internal
bash# DNS 해석 테스트 (dig - 가장 상세) dig example.com dig example.com @8.8.8.8 # 특정 DNS 서버로 조회 dig +short example.com # IP만 출력 # nslookup (간단) nslookup example.com # getent: /etc/hosts + DNS 통합 해석 (애플리케이션과 동일한 경로) getent hosts example.com # systemd-resolved 상태 systemd-resolve --status resolvectl status
`/etc/nsswitch.conf` — 이름 해석 우선순위 결정:
bashgrep hosts /etc/nsswitch.conf # hosts: files dns myhostname # files(=/etc/hosts) → dns 순서
컨테이너/쿠버네티스 환경 주의사항:
- 컨테이너 내
/etc/resolv.conf는 호스트와 다름 (Docker가 자동 생성) - K8s Pod은 CoreDNS를 nameserver로 사용
search도메인이 길면 DNS 쿼리가 여러 번 시도됨 (레이턴시 증가)
bashcat /etc/resolv.conf && cat /etc/hosts
증상: ss -tlnp로 포트가 LISTEN 중인 것을 확인했는데, 외부 클라이언트에서 접속이 거부됩니다.
원인 분류 및 진단:
1단계: 바인딩 주소 확인 — 서비스가 어떤 주소에 바인드됐는지 확인합니다:
bashss -tlnp | grep :8080 # LISTEN 0 128 127.0.0.1:8080 ← 루프백만! 외부 접근 불가 # LISTEN 0 128 0.0.0.0:8080 ← 정상 (모든 인터페이스)
애플리케이션이 127.0.0.1에만 바인딩했다면 설정 파일에서 0.0.0.0 또는 :: (IPv6)로 변경합니다.
2단계: iptables/nftables 방화벽 확인 — 방화벽 규칙에서 해당 포트가 허용됐는지 확인합니다:
bash# iptables 규칙 확인 sudo iptables -L INPUT -n -v --line-numbers sudo iptables -L FORWARD -n -v # 특정 포트 관련 규칙만 필터 sudo iptables -L -n | grep 8080 # nftables (최신 배포판) sudo nft list ruleset # ufw (Ubuntu) sudo ufw status verbose
2단계-b: iptables로 포트 허용 — 방화벽에서 해당 포트의 인바운드 트래픽을 허용합니다:
bash# 포트 8080 허용 (영구 저장은 iptables-save 또는 ufw 사용) sudo iptables -A INPUT -p tcp --dport 8080 -j ACCEPT # ufw 사용 시 sudo ufw allow 8080/tcp # firewalld (RHEL/CentOS 계열) sudo firewall-cmd --add-port=8080/tcp --permanent sudo firewall-cmd --reload
3단계: 클라우드/하이퍼바이저 보안 그룹
AWS Security Group, GCP Firewall Rules, Azure NSG는 OS 내부 방화벽과 별개입니다. 클라우드 콘솔에서 인바운드 규칙을 확인합니다.
4단계: 클라이언트 측에서 연결 테스트 — nc나 telnet으로 클라이언트에서 직접 포트 연결을 테스트합니다:
bash# TCP 연결 가능 여부 확인 nc -zv 10.0.1.15 8080 # Connection to 10.0.1.15 8080 port [tcp/*] succeeded! # curl로 HTTP 확인 curl -v http://10.0.1.15:8080/health # telnet (기본 도구) telnet 10.0.1.15 8080
빠른 진단 체크리스트:
ss -tlnp | grep <포트>— 리스닝 중인가? 어느 주소에 바인딩?iptables -L INPUT -n | grep <포트>— OS 방화벽 차단?- 클라우드 콘솔 — 보안 그룹/방화벽 룰 차단?
nc -zv <서버IP> <포트>— 실제 TCP 연결 가능?
증상: curl https://api.example.com에서 Could not resolve host: api.example.com 오류 발생.
단계별 진단:
1단계: 기본 DNS 해석 테스트 — dig, nslookup으로 DNS 해석이 정상 동작하는지 확인합니다:
bash# DNS 없이 IP 직접 연결 테스트 (DNS 문제인지 확인) curl -v --resolve api.example.com:443:93.184.216.34 https://api.example.com # 공용 DNS로 직접 조회 dig api.example.com @8.8.8.8 dig api.example.com @1.1.1.1 # 로컬 DNS 서버로 조회 dig api.example.com
2단계: resolv.conf 확인 — /etc/resolv.conf에 올바른 네임서버가 설정됐는지 확인합니다:
bashcat /etc/resolv.conf # nameserver가 비어있거나 없는 경우 # nameserver가 응답 없는 서버를 가리키는 경우
bash# nameserver에 직접 ping ping -c 3 $(grep nameserver /etc/resolv.conf | head -1 | awk '{print $2}')
3단계: systemd-resolved 확인 (Ubuntu 18.04+) — Ubuntu 18.04 이후 systemd-resolved 상태를 확인합니다:
bashsystemctl status systemd-resolved # 재시작 sudo systemctl restart systemd-resolved # stub resolver 상태 resolvectl status # DNS 캐시 초기화 sudo resolvectl flush-caches
4단계: 컨테이너 환경 — 컨테이너에서 DNS가 안 되면 Docker 내부 DNS 설정을 확인합니다:
bash# 컨테이너 내부에서 확인 docker exec -it <container> cat /etc/resolv.conf docker exec -it <container> nslookup google.com # Docker 데몬 DNS 설정 cat /etc/docker/daemon.json # {"dns": ["8.8.8.8", "8.8.4.4"]}
일반적인 원인과 해결 — DNS 장애의 흔한 원인별 증상과 해결 방법을 정리했습니다:
| 원인 | 증상 | 해결 |
|---|---|---|
| nameserver 미설정 | /etc/resolv.conf 비어있음 |
nameserver 8.8.8.8 추가 |
| systemd-resolved 다운 | 127.0.0.53 응답 없음 |
systemctl restart systemd-resolved |
/etc/hosts 잘못된 항목 |
특정 호스트만 실패 | /etc/hosts 확인 및 수정 |
| 내부 DNS 서버 다운 | 사내 도메인만 실패 | 내부 DNS 서버 상태 확인 |
| 방화벽 UDP 53 차단 | 외부 도메인 실패 | iptables -A INPUT -p udp --dport 53 -j ACCEPT |
증상: 고트래픽 서버에서 connect: Cannot assign requested address 오류, 또는 새 연결을 못 맺음.
원인: TCP 연결 종료 후 OS는 일정 시간(기본 60초) 동안 소켓을 TIME_WAIT 상태로 유지합니다. 클라이언트 측 ephemeral 포트(기본 32768-60999, 약 28231개)가 소진되면 새 연결을 못 맺습니다.
1단계: 현재 상태 확인 — TIME_WAIT 소켓이 얼마나 쌓여 있는지 확인합니다:
bash# TIME_WAIT 소켓 수 확인 ss -ant | grep TIME-WAIT | wc -l # 상태별 통계 ss -s # 상세 TIME_WAIT 소켓 목록 ss -ant state time-wait | head -20
TIME-WAIT 0 0 10.0.1.15:52341 10.0.1.20:80 TIME-WAIT 0 0 10.0.1.15:52342 10.0.1.20:80 ... (수천 개)
2단계: Ephemeral 포트 범위 확인 — 사용 가능한 클라이언트 포트 범위가 좁으면 포트 고갈이 빨리 옵니다:
bashcat /proc/sys/net/ipv4/ip_local_port_range # 32768 60999 ← 사용 가능 포트: 28231개
3단계: 커널 파라미터 튜닝 — sysctl로 포트 범위를 넓히고 TIME_WAIT 재사용을 활성화합니다:
bash# Ephemeral 포트 범위 확장 sudo sysctl -w net.ipv4.ip_local_port_range="1024 65535" # TIME_WAIT 소켓을 새 연결에 재사용 (아웃바운드) sudo sysctl -w net.ipv4.tcp_tw_reuse=1 # TIME_WAIT 타임아웃 확인 (변경 권장 안 함) cat /proc/sys/net/ipv4/tcp_fin_timeout # 영구 적용 (/etc/sysctl.conf 또는 /etc/sysctl.d/99-network.conf) cat >> /etc/sysctl.d/99-network.conf << 'EOF' net.ipv4.ip_local_port_range = 1024 65535 net.ipv4.tcp_tw_reuse = 1 EOF sudo sysctl -p /etc/sysctl.d/99-network.conf
4단계: 근본 원인 해결 (권장)
- HTTP Keep-Alive 활성화 (연결 재사용으로 TIME_WAIT 감소)
- 연결 풀링 사용 (DB 연결, 백엔드 API 호출)
- 로드밸런서에서 연결 수명 관리
주의: tcp_tw_recycle은 Linux 4.12에서 제거됨. NAT 환경에서 문제를 일으킬 수 있어 사용하지 마세요.
상황: 새 서비스를 시작하려는데 bind: address already in use 오류가 발생합니다.
bash$ sudo systemctl start my-service Job for my-service.service failed. See "journalctl -xe" for details. $ journalctl -u my-service -n 20 Error: listen tcp 0.0.0.0:8080: bind: address already in use
체계적 진단 순서:
1. 어떤 프로세스가 포트를 점유하고 있는가? — ss나 lsof로 해당 포트를 사용 중인 PID를 찾습니다:
bash# ss로 확인 (가장 빠름) sudo ss -tlnp sport = :8080 # lsof으로 확인 (파일 기반) sudo lsof -i :8080 # fuser으로 확인 sudo fuser 8080/tcp
출력 예시:
LISTEN 0 128 0.0.0.0:8080 0.0.0.0:* users:(("node",pid=4521,fd=15))
2. 해당 프로세스가 무엇인가? — PID로 프로세스 이름과 실행 경로를 확인합니다:
bash# PID로 프로세스 상세 확인 ps aux | grep 4521 cat /proc/4521/cmdline | tr '\0' ' ' # 어떤 서비스인지 확인 systemctl status $(ps -o unit= -p 4521)
3. 의도치 않은 프로세스라면 종료 — 의도하지 않은 프로세스가 포트를 점유 중이면 종료합니다:
bash# 정상 종료 시도 kill -15 4521 # 서비스로 관리되는 경우 sudo systemctl stop old-service # 강제 종료 (최후 수단) kill -9 4521
4. 의도적인 충돌이라면 포트 변경 — 두 서비스가 같은 포트를 쓰면 한쪽을 변경합니다:
bash# 새 서비스 설정 파일에서 포트 변경 # 예: /etc/my-service/config.yaml port: 8081 # 또는 환경변수로 PORT=8081 ./my-service
5. 서비스 재시작 후 확인 — 포트 변경 후 서비스를 재시작하고 정상 바인딩됐는지 확인합니다:
bashsudo systemctl start my-service sudo systemctl status my-service ss -tlnp sport = :8081
팁: 서비스 시작 스크립트에 미리 포트 검사를 추가하면 충돌을 조기에 발견할 수 있습니다:
bashif ss -tlnp | grep -q ":$PORT "; then echo "ERROR: Port $PORT is already in use" exit 1 fi
상황: 프로덕션 API 응답 시간이 평소 50ms에서 갑자기 2초로 증가했습니다. 알림이 울렸고 빠르게 원인을 파악해야 합니다.
체계적 트리아지 순서 (L2 → L3 → L4 → L7):
1단계: 기본 연결성 (L3) — 1분 — ping으로 3계층(IP) 연결 가능 여부를 먼저 확인합니다:
bash# 게이트웨이 응답 확인 ping -c 5 $(ip route show default | awk '{print $3}') # 외부 인터넷 연결 ping -c 5 8.8.8.8 # DNS 응답 시간 time dig api.upstream.com @8.8.8.8
2단계: 경로 확인 (L3) — 2분 — traceroute나 mtr로 어느 홉에서 패킷이 멈추는지 확인합니다:
bash# 목적지까지 각 홉 지연 측정 mtr --report --report-cycles 20 10.0.2.50 # 특정 구간에서 패킷 로스가 있는가?
3단계: 소켓 상태 (L4) — 2분 — ss로 포트가 열려 있고 서비스가 바인드됐는지 확인합니다:
bash# 연결 상태 요약 ss -s # CLOSE_WAIT, TIME_WAIT 과다 여부 ss -ant | awk '{print $1}' | sort | uniq -c | sort -rn # Recv-Q가 쌓인 소켓 (처리 백로그) ss -tnp | awk '$2 > 0 {print}' # SYN backlog (SYN flood 또는 accept 큐 포화) ss -lnt | awk 'NR>1 {print $2, $4}' | grep -v "^0 "
4단계: 실시간 패킷 분석 (L4) — 3분 — tcpdump로 패킷이 실제로 도달하는지 확인합니다:
bash# 백엔드 API 포트 트래픽 캡처 (30초) sudo tcpdump -i eth0 host 10.0.2.50 and port 8080 -w /tmp/prod-$(date +%s).pcap -G 30 -W 1 # 재전송(Retransmit) 패킷 수 실시간 확인 watch -n 1 'cat /proc/net/snmp | grep -E "^Tcp:" | awk NR==2 | awk "{print \"Retrans:\", \$13, \"OutSegs:\", \$11}"'
5단계: 애플리케이션 계층 (L7) — 2분 — curl과 서비스 로그로 앱 레벨 문제를 확인합니다:
bash# 응답 시간 분해 curl -o /dev/null -s -w \ "DNS:%{time_namelookup} TCP:%{time_connect} TLS:%{time_appconnect} TTFB:%{time_starttransfer} Total:%{time_total}\n" \ https://api.upstream.com/health # 에러율 확인 (nginx/haproxy 로그) tail -f /var/log/nginx/access.log | awk '{print $9}' | sort | uniq -c # 애플리케이션 로그 확인 journalctl -u my-service -n 100 --since "10 min ago" | grep -E "ERROR|WARN|timeout"
일반적인 원인과 해결 패턴 — 증상별로 가장 흔한 원인과 해결 방법을 정리했습니다:
| 증상 | 원인 | 해결 |
|---|---|---|
| mtr에서 특정 홉 레이턴시 급등 | 네트워크 장비 문제 | 네트워크 팀 에스컬레이션 |
| Recv-Q 큰 소켓 다수 | 애플리케이션 처리 병목 | 스레드/프로세스 증가, 프로파일링 |
| TCP Retransmit 급증 | 패킷 로스 | 네트워크 품질 확인, NIC 드라이버 |
| TTFB만 높음 | DB 쿼리 슬로우, 외부 API 지연 | DB slow query 로그, 의존 서비스 확인 |
| TIME_WAIT 급증 | 연결 풀 없는 단발성 연결 | Keep-Alive 또는 연결 풀 적용 |
기억할 원칙: 네트워크 지연은 대부분 단일 원인이 아닙니다. 계층별로 데이터를 수집하고, 정상 상태의 베이스라인과 비교해야 합니다. 프로덕션에서 tcpdump를 장시간 실행하면 디스크가 꽉 찰 수 있으니 -G(rotate interval)와 -W(file count) 플래그로 제한합니다.
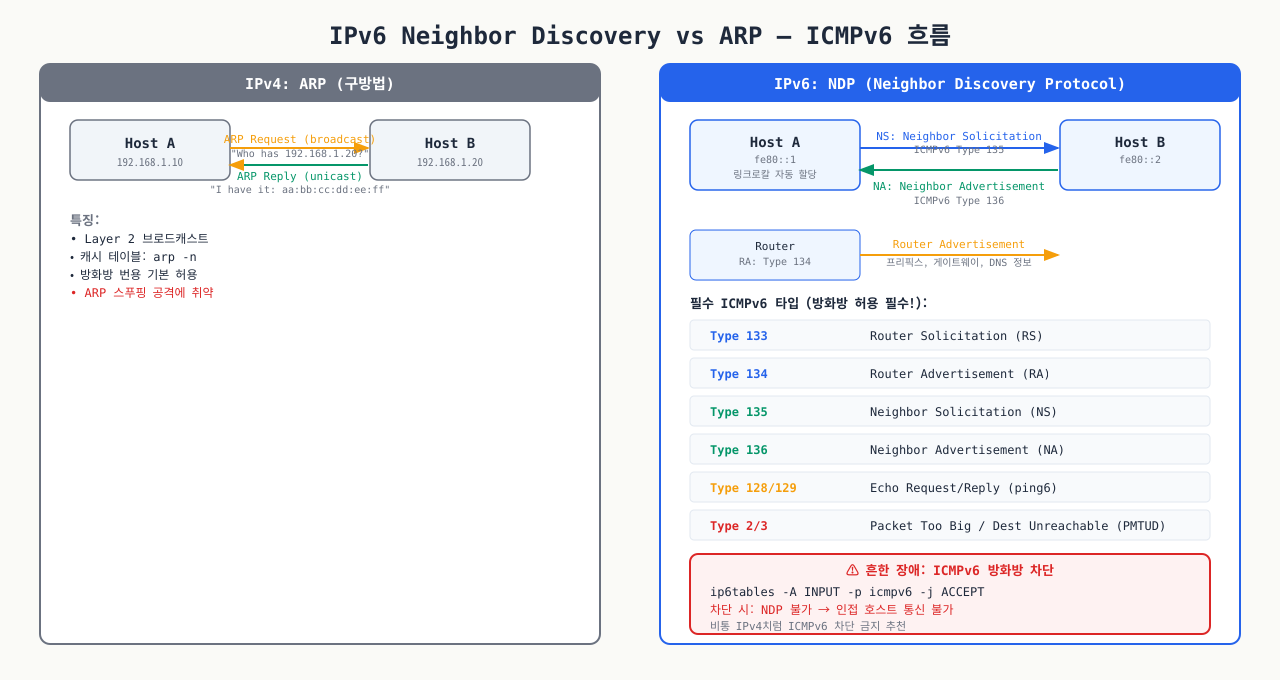
IPv4만 설정하고 IPv6를 방치하면 "IPv6로만 통신하는 서비스에 접속 안 됨" 또는 "IPv4 방화벽은 열었는데 IPv6 경로로 차단" 같은 장애가 발생합니다.
IPv6 주소 구조 기초 — IPv6 주소 형식과 Link-Local, Loopback 주소의 의미를 파악합니다:
bash# 현재 IPv6 주소 확인 ip -6 addr show # inet6 2001:db8::1/64 scope global ← 글로벌 유니캐스트 (인터넷 라우팅 가능) # inet6 fe80::1/64 scope link ← 링크-로컬 (같은 세그먼트 내 통신) # inet6 ::1/128 scope host ← 루프백 (127.0.0.1에 해당) # IPv6 라우팅 테이블 확인 ip -6 route show
ICMPv6 — IPv6의 핵심 제어 프로토콜 (차단 금지):
ICMPv6은 IPv4의 ARP 역할(Neighbor Discovery)을 담당하므로 차단하면 IPv6 통신 자체가 불가합니다.
| ICMPv6 타입 | 역할 | 차단 시 영향 |
|---|---|---|
| 133 (RS) | Router Solicitation | 기본 게이트웨이 미발견 |
| 134 (RA) | Router Advertisement | 자동 주소 설정 실패 |
| 135 (NS) | Neighbor Solicitation | ARP 역할 — 통신 불가 |
| 136 (NA) | Neighbor Advertisement | ARP 역할 — 통신 불가 |
| 128 (Echo Request) | ping6 | ping 실패 |
bash# IPv6 연결 테스트 ping6 -c 3 2606:4700:4700::1111 # Cloudflare DNS ping6 -c 3 ipv6.google.com # IPv6 전용 연결 확인 (curl) curl -6 -v https://ipv6.google.com 2>&1 | head -20 # IPv6 라우팅 문제 진단 traceroute6 ipv6.google.com
흔한 IPv4-only 방화벽 장애 — IPv4 방화벽만 설정하면 IPv6 경로로 우회 접근이 가능한 취약점이 생깁니다:
bash# iptables로 IPv4만 열고 ip6tables는 기본 DROP인 경우 # → IPv6로 접속 시도 시 silently dropped # 확인: ip6tables 기본 정책 sudo ip6tables -L -n | grep "policy" # 임시 해결: IPv6 전체 허용 (보안 설정은 추후) sudo ip6tables -P INPUT ACCEPT sudo ip6tables -P FORWARD ACCEPT sudo ip6tables -P OUTPUT ACCEPT
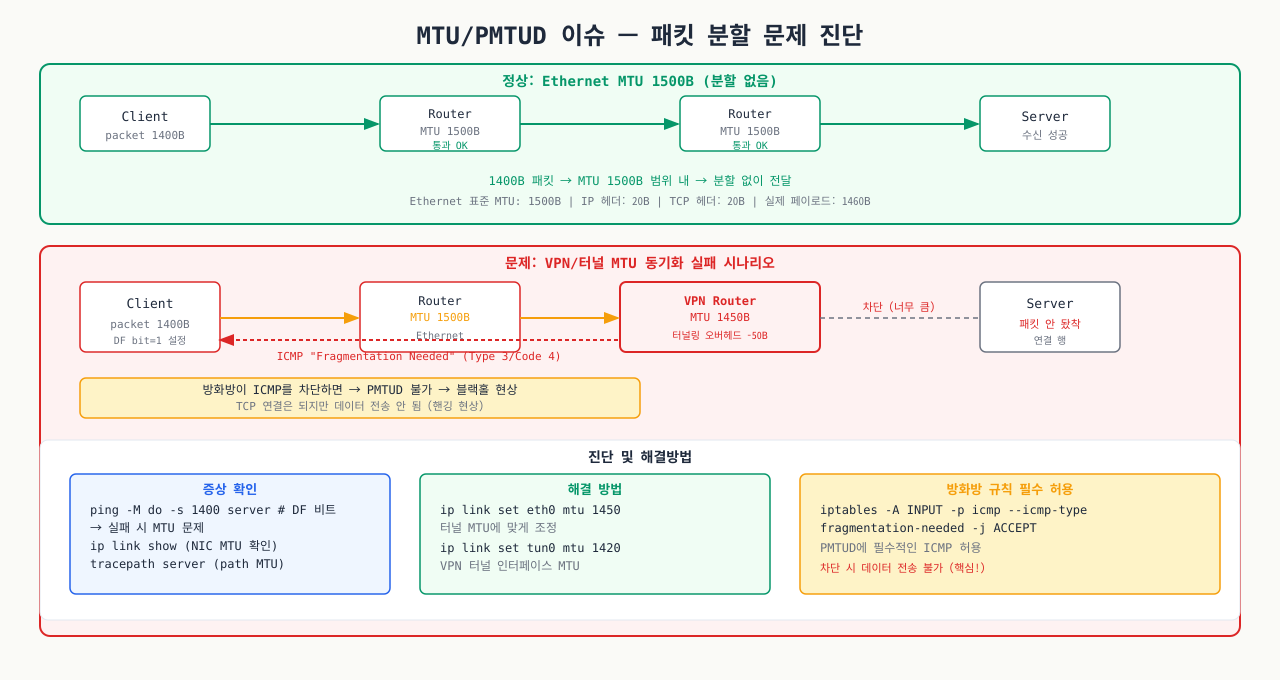
MTU(Maximum Transmission Unit) 불일치는 "일부 사이트만 안 됨", "작은 패킷은 되는데 큰 파일 전송이 실패" 같은 간헐적 장애를 만듭니다.
MTU 기본값과 문제 상황 — 환경별 MTU 기본값과 불일치 시 발생하는 증상을 정리했습니다:
| 환경 | 일반적인 MTU |
|---|---|
| Ethernet | 1500 bytes |
| VPN (OpenVPN/WireGuard) | 1420~1450 bytes |
| AWS VPC | 9001 bytes (Jumbo Frame) |
| Docker bridge | 1500 bytes (호스트와 동일) |
MTU 진단 명령 — ping의 -M do 옵션으로 경로 MTU를 단계적으로 탐색합니다:
bash# 현재 인터페이스 MTU 확인 ip link show | grep mtu # PMTUD 테스트 — 분할 금지(DF bit) 패킷으로 최대 MTU 측정 ping -M do -s 1472 8.8.8.8 # -M do: Don't Fragment 설정 # -s 1472: 데이터 크기 (1472 + 28 ICMP 헤더 = 1500) # 실패하면 "Frag needed" — MTU 이슈 확인 # 작동하는 최대 크기 찾기 (이진 탐색) for size in 1472 1400 1300 1200; do if ping -M do -s $size -c 1 -W 2 8.8.8.8 &>/dev/null; then echo "MTU OK: $((size + 28))" break fi done # tracepath로 경로상 MTU 확인 tracepath 8.8.8.8 # 결과에서 "pmtu XXXX" 가 경로상 최소 MTU
VPN 환경 MTU 조정 — VPN 터널 오버헤드를 고려해 MTU를 낮게 설정합니다:
bash# WireGuard 인터페이스 MTU 조정 (/etc/wireguard/wg0.conf) [Interface] MTU = 1420 # 1500 - 80 (WireGuard 오버헤드) # OpenVPN 클라이언트 설정 tun-mtu 1420 fragment 1300 mssfix 1260
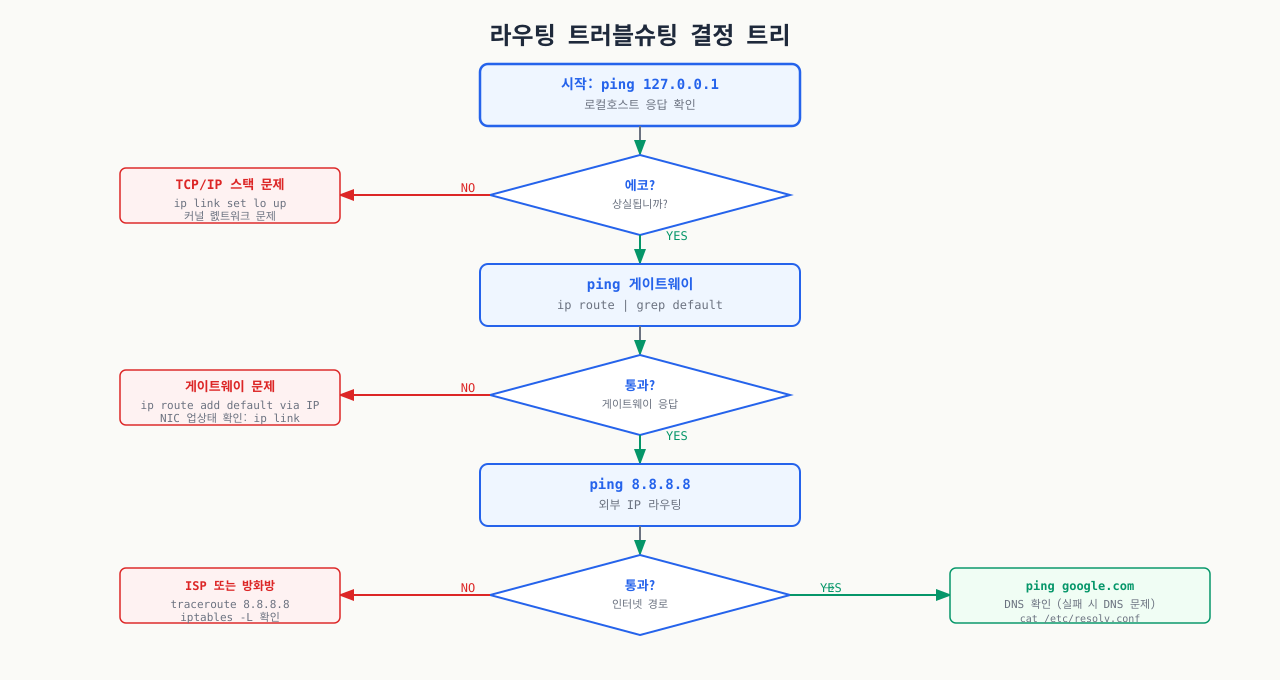
서버를 재부팅했더니 외부 통신이 안 됩니다. ping 8.8.8.8도 안 되고, curl도 안 됩니다. 그런데 같은 서브넷의 다른 서버로는 통신이 됩니다. 이런 상황에서 열이면 아홉은 기본 게이트웨이가 없거나 라우팅 테이블이 잘못된 경우입니다. 또는 서버에 NIC가 두 개인데 두 인터페이스로 들어온 트래픽이 뒤섞이면서 예상치 못한 경로로 나가는 비대칭 라우팅 문제도 있습니다. 라우팅 문제는 "어디까지는 되고 어디서부터 안 되는지"를 단계별로 좁혀가는 게 핵심입니다.
기본 라우팅 문제 진단 순서 — 기본 게이트웨이 누락 여부부터 단계적으로 라우팅 문제를 좁혀갑니다:
bash# 1. 현재 라우팅 테이블 확인 ip route show # default via 192.168.1.1 dev eth0 ← 기본 게이트웨이 # 192.168.1.0/24 dev eth0 proto kernel ← 직접 연결 네트워크 # 2. 특정 목적지로의 라우트 확인 ip route get 8.8.8.8 # 8.8.8.8 via 192.168.1.1 dev eth0 src 192.168.1.100 # 3. 게이트웨이 연결 확인 ping -c 3 192.168.1.1 # 4. 라우팅 트레이스 traceroute 8.8.8.8
정적 라우트 추가 (임시/영구) — 특정 네트워크로 가는 경로를 수동으로 추가합니다:
bash# 임시 (재부팅 시 사라짐) sudo ip route add 10.0.0.0/8 via 192.168.1.254 # 영구 (Ubuntu/Debian — netplan) # /etc/netplan/00-installer-config.yaml network: ethernets: eth0: routes: - to: 10.0.0.0/8 via: 192.168.1.254 sudo netplan apply # 영구 (RHEL — nmcli) sudo nmcli connection modify eth0 +ipv4.routes "10.0.0.0/8 192.168.1.254" sudo nmcli connection up eth0
다음 모듈에서는 DNS 심화 — /etc/resolv.conf, systemd-resolved, dig로 이름 해석 과정을 단계별로 추적하고 DNS 장애를 진단하는 방법을 다룹니다.
'Linux' 카테고리의 다른 글
| [Linux] 포트 & 네트워크 진단 (0) | 2026.05.22 |
|---|---|
| [Linux] DNS & 이름 해석 트러블슈팅 (0) | 2026.05.22 |
| [Linux] 디스크 트러블슈팅 (0) | 2026.05.22 |
| [Linux] LVM & 볼륨 관리 (0) | 2026.05.22 |
| [Linux] 디스크와 스토리지 관리 (0) | 2026.05.22 |