개발자가 슬랙에 메시지를 보냅니다. "DB 접속이 안 돼요." 서버에서 telnet db-host 5432를 쳐보면 Connection refused. 애플리케이션 로그에는 "connection refused"만 찍혀 있습니다. DB 서버가 죽었는지, 포트가 다른지, 방화벽인지 — 소켓 상태를 읽을 줄 알면 1분 안에 좁힐 수 있습니다.
ss -tulnp | grep 5432 — 이 한 줄이 시작입니다.
포트 & 네트워크 진단
ss --version && nc -h 2>&1 | head -1 && tcpdump --version 2>&1 | head -1
sudo apt install -y netcat-openbsd # Ubuntu/Debian\nsudo dnf install -y nmap-ncat # RHEL/CentOS
sudo apt install -y tcpdump # Ubuntu/Debian\nsudo dnf install -y tcpdump # RHEL/CentOS
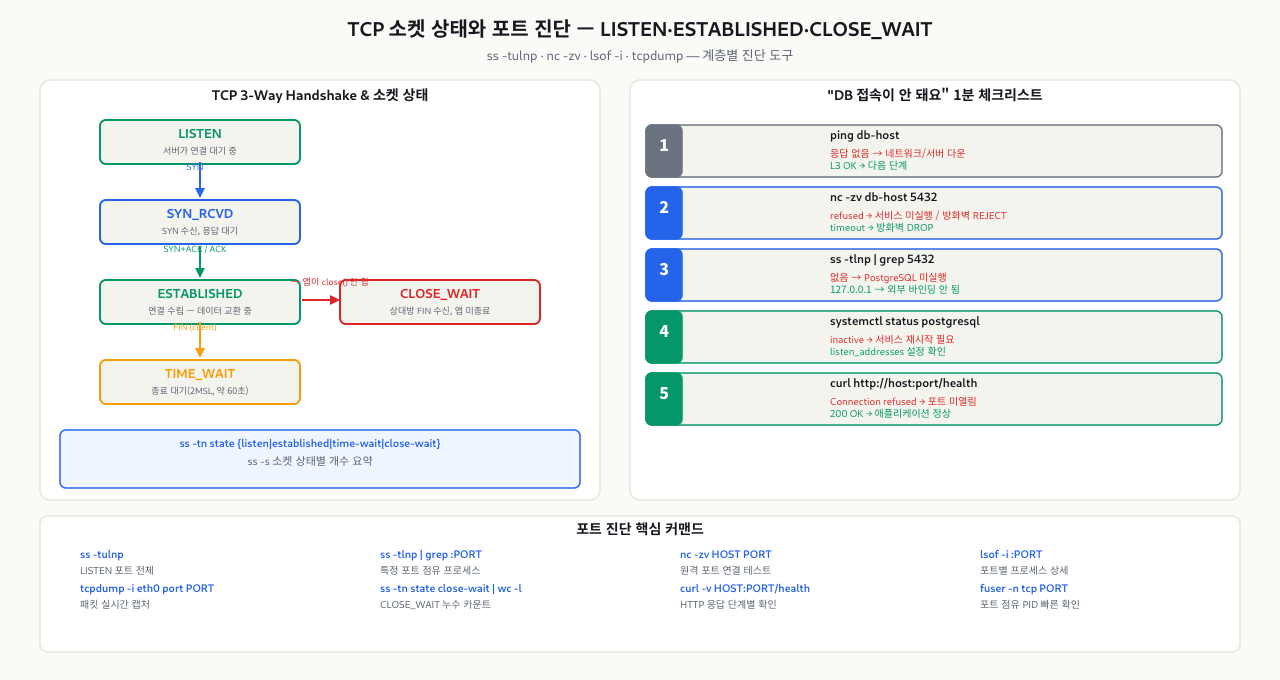
telnet 192.168.1.100 3306을 실행했을 때 바로 "Connected"가 뜨면 포트가 열린 것이고, 아무 반응이 없으면 방화벽이 차단하고 있는 것입니다. 그런데 왜 어떤 경우는 즉시 오류가 뜨고 어떤 경우는 타임아웃까지 기다려야 할까요? TCP 연결은 SYN → SYN-ACK → ACK 세 단계를 거쳐 수립됩니다. 이 핸드셰이크 과정에서 어느 단계가 실패했는지를 보면 문제가 방화벽인지, 서비스가 안 떠있는지, 아니면 바인드 주소 설정인지 구분할 수 있습니다. ss나 tcpdump가 보여주는 상태값(SYN_SENT, ESTABLISHED, CLOSE_WAIT 등)을 이해하는 것도 이 핸드셰이크 구조에서 출발합니다.
네트워크 진단 도구를 제대로 활용하려면 TCP 연결이 어떤 단계를 거쳐 수립되는지 이해해야 합니다. TCP는 데이터를 전송하기 전에 반드시 3-Way Handshake를 통해 연결을 수립합니다.
클라이언트 (192.168.1.10) 서버 (192.168.1.20:5432) | | | 1. SYN (seq=100) | | --------------------------------> | "연결해도 될까요?" | | | 2. SYN-ACK (seq=300, ack=101) | | <-------------------------------- | "됩니다, 확인했습니다" | | | 3. ACK (ack=301) | | --------------------------------> | "감사합니다, 시작하죠" | | | [데이터 전송 시작] |
각 단계 설명 — TCP 연결 수립 시 각 패킷 교환 단계별 의미와 소켓 상태를 정리했습니다:
| 단계 | 패킷 | 의미 | 소켓 상태 |
|---|---|---|---|
| 1단계 | SYN | 클라이언트가 서버에 연결 요청 | 클라이언트: SYN_SENT |
| 2단계 | SYN-ACK | 서버가 요청 수락, 자신도 동기화 요청 | 서버: SYN_RECEIVED |
| 3단계 | ACK | 클라이언트가 수락 확인 | 양쪽: ESTABLISHED |
핵심 소켓 상태 — ss나 netstat 출력에서 자주 등장하는 상태값의 의미입니다:
| 상태 | 의미 | 언제 나타나는가 |
|---|---|---|
LISTEN |
서버가 연결 대기 중 | 포트를 바인딩하고 연결을 기다리는 서비스 |
ESTABLISHED |
연결이 수립되어 데이터 전송 중 | 클라이언트-서버 간 활성 연결 |
TIME_WAIT |
연결 종료 후 대기 (약 60초) | 기존 패킷이 재전송될 경우를 대비한 대기 |
CLOSE_WAIT |
상대방이 연결을 끊었지만 내쪽은 아직 닫지 않음 | 애플리케이션 소켓 미반환 버그 의심 |
SYN_SENT |
SYN을 보내고 SYN-ACK를 기다리는 중 | 연결 시도 중 (방화벽 차단 시 이 상태에서 멈춤) |
LISTEN vs ESTABLISHED 차이:
LISTEN 상태는 "문을 열고 손님을 기다리는" 상태입니다. ss -tulnp 명령어로 확인할 때 보이는 포트가 바로 이 상태입니다. ESTABLISHED는 실제 손님(클라이언트)이 들어와서 대화 중인 상태로, 연결이 성공적으로 수립된 것을 의미합니다.
bash# LISTEN 상태만 확인 (서비스가 어떤 포트에서 기다리는지) ss -tlnp # ESTABLISHED 상태만 확인 (현재 활성 연결) ss -tnp state established # TIME_WAIT가 많으면 단시간에 연결이 폭증했다는 신호 ss -s # 상태별 요약 통계
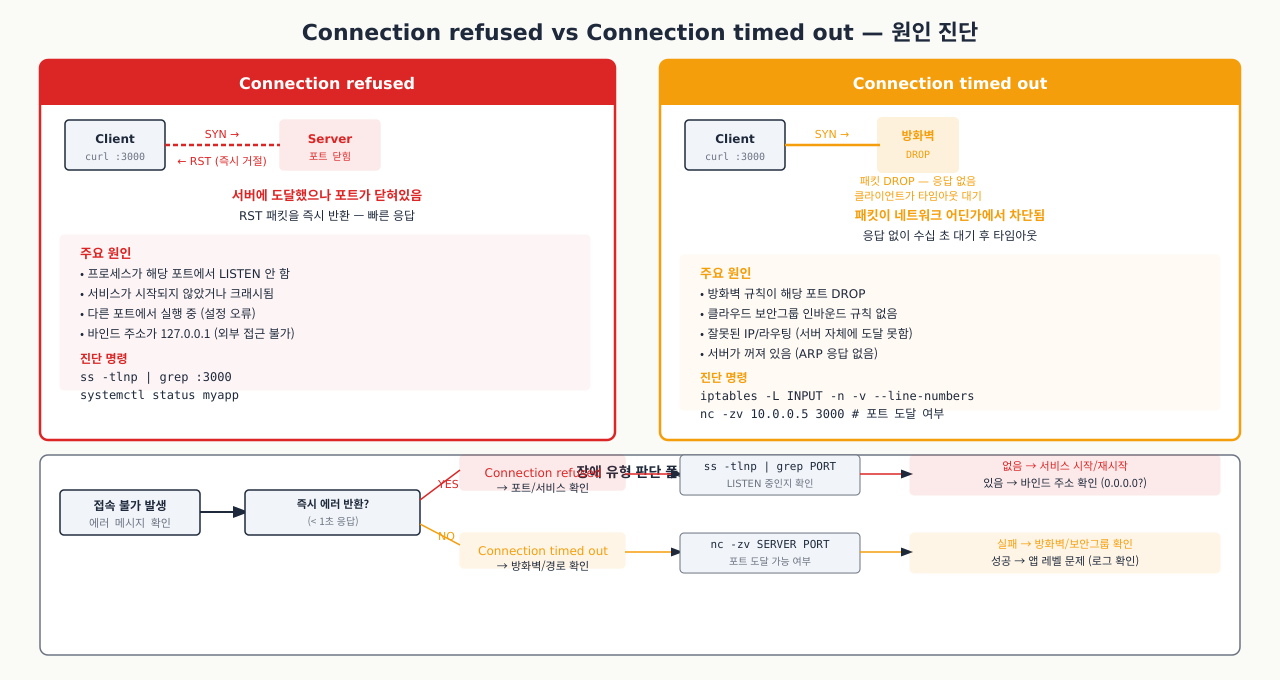
API 서버에서 데이터베이스 접속 오류가 났는데 로그에는 "Connection timed out"이 찍혔습니다. DBA는 "DB 서버는 살아있다"고 하고, 네트워크 팀은 "방화벽에서 막은 거 없다"고 했습니다. 같은 연결 실패처럼 보이지만 "Connection refused"와 "Connection timed out"은 원인이 완전히 다릅니다. 이 두 메시지를 구별하는 것만으로도 문제가 방화벽인지, 서비스가 안 떠있는지, 바인드 주소 문제인지 즉시 방향을 잡을 수 있습니다.
네트워크 연결 오류 메시지는 크게 두 가지로 나뉩니다. 이 둘을 구별하면 문제의 원인을 방화벽인지 서비스 다운인지 즉시 파악할 수 있습니다.
Connection refused (연결 거부) — 포트에 서비스가 없거나 방화벽이 REJECT로 차단할 때 나타납니다:
bash$ nc -zv 192.168.1.20 5432 nc: connect to 192.168.1.20 port 5432 (tcp) failed: Connection refused
- 목적지 서버까지 패킷이 도달했지만 해당 포트에서 들어주는 서비스가 없음
- TCP RST(Reset) 패킷이 즉시 반환됨 → 응답이 매우 빠름 (수 밀리초 이내)
- 원인: 서비스가 다운되었거나, 다른 포트에서 실행 중이거나, 서버 자체 방화벽(iptables/firewalld)이 REJECT 설정됨
Connection timed out (연결 시간 초과) — 방화벽이 DROP으로 패킷을 버려 클라이언트가 응답을 기다리다 포기합니다:
bash$ nc -zv 192.168.1.20 5432 (아무 반응 없이 수십 초 후...) nc: connect to 192.168.1.20 port 5432 (tcp) failed: Connection timed out
- SYN 패킷을 보냈지만 응답이 전혀 없음 → 패킷이 어딘가에서 차단(DROP) 됨
- 응답이 없으므로 타임아웃까지 기다려야 함 (기본 수십 초~수 분)
- 원인: 네트워크 방화벽(AWS Security Group, 클라우드 방화벽, 중간 라우터)이 패킷을 DROP하고 있음
진단 요약표 — 증상별로 오류 메시지, 응답 속도, 원인을 한눈에 비교합니다:
| 증상 | 오류 메시지 | 응답 속도 | 가능한 원인 |
|---|---|---|---|
| 서비스 미실행 / REJECT 방화벽 | Connection refused |
빠름 (ms) | 서비스 다운, 포트 오류, iptables REJECT |
| 패킷 DROP 방화벽 | Connection timed out |
느림 (수십 초) | 클라우드 보안그룹, 중간 방화벽 DROP |
| 서비스 정상 | Connected / 200 OK |
빠름 (ms) | 정상 |
실제 진단 흐름 — 포트 문제가 발생했을 때 단계적으로 원인을 좁혀가는 과정입니다:
bash# 1단계: refused인가 timeout인가 확인 (최대 5초만 기다림) nc -zv -w 5 DB_HOST 5432 # refused → 서버 측에서 ss -tlnp로 포트 확인 # timeout → 네트워크/방화벽 레이어 확인 (ping, traceroute) # connected → L7(애플리케이션) 레이어 문제
실습 전 디렉토리와 예제 파일을 먼저 준비합니다.
bash# 실습 디렉토리 준비 mkdir -p /tmp/linux/part4/exam_2 && cd /tmp/linux/part4/exam_2 # 포트 진단용 테스트 서버 스크립트 생성 cat > /tmp/linux/part4/exam_2/test_server.sh << 'EOF' #!/bin/bash # 포트 진단 실습용 간단한 TCP 서버 PORT="${1:-9999}" echo "테스트 서버 시작 (포트: $PORT)" while true; do echo "HTTP/1.1 200 OK\r\nContent-Length: 2\r\n\r\nOK" | nc -l -p "$PORT" -q 1 2>/dev/null || \ nc -l "$PORT" <<< $'HTTP/1.1 200 OK\r\nContent-Length: 2\r\n\r\nOK' 2>/dev/null done EOF chmod +x /tmp/linux/part4/exam_2/test_server.sh
이제 실습을 진행합니다.
ss는 Socket Statistics의 약자로, netstat을 완전히 대체하는 현대적인 도구입니다. /proc/net 파일시스템을 직접 읽어 속도가 훨씬 빠르고 더 많은 정보를 제공합니다.
각 옵션의 정확한 의미 — ss -tulnp에서 각 플래그가 무엇을 출력하는지 설명합니다:
| 옵션 | 의미 | 기억법 |
|---|---|---|
-t |
TCP 소켓만 표시 | TCP |
-u |
UDP 소켓만 표시 | UDP |
-l |
LISTEN 상태인 소켓만 표시 | Listen |
-n |
호스트/포트를 숫자로 표시 (DNS 역조회 안 함) | Numeric |
-p |
소켓을 사용 중인 프로세스 정보 표시 | Process |
-a |
모든 소켓 표시 (LISTEN + ESTABLISHED 등) | All |
bash# 가장 많이 쓰는 조합: TCP/UDP LISTEN 포트와 프로세스 이름 한 번에 ss -tulnp
실제 출력 예시 및 각 컬럼 해석 — ss 출력에서 각 컬럼이 어떤 정보를 담고 있는지 확인합니다:
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port Process tcp LISTEN 0 128 0.0.0.0:22 0.0.0.0:* users:(("sshd",pid=1234,fd=3)) tcp LISTEN 0 128 127.0.0.1:5432 0.0.0.0:* users:(("postgres",pid=2345,fd=5)) tcp LISTEN 0 511 0.0.0.0:80 0.0.0.0:* users:(("nginx",pid=3456,fd=6)) tcp LISTEN 0 128 :::8080 :::* users:(("java",pid=4567,fd=21)) udp UNCONN 0 0 0.0.0.0:68 0.0.0.0:* users:(("dhclient",pid=890,fd=6))
컬럼별 의미:
Netid: 프로토콜 종류 (tcp, udp, unix 등)State: 소켓 상태 (LISTEN, ESTABLISHED, TIME_WAIT 등)Recv-Q: 수신 버퍼에 쌓인 바이트 수 (0이 정상; 크면 애플리케이션이 느리게 처리 중)Send-Q: 송신 버퍼에 쌓인 바이트 수 (0이 정상; 크면 네트워크 병목)Local Address:Port: 바인딩된 로컬 주소와 포트0.0.0.0:22→ 모든 IPv4 인터페이스에서 수신127.0.0.1:5432→ 루프백(로컬)에서만 수신 (외부 접근 불가!):::8080→ 모든 IPv6 인터페이스 (IPv4도 포함하는 경우 많음)
Peer Address:Port: 연결 상대방 주소 (LISTEN이면*)Process:pid와 프로세스 이름 (root 권한 필요, 없으면 표시 안 됨)
자주 쓰는 ss 변형 명령어 — 상황에 맞게 조합해 쓰는 ss 명령어 패턴 모음입니다:
bash# 특정 포트만 필터링 ss -tlnp | grep :8080 # ESTABLISHED 연결만 (현재 접속자 확인) ss -tnp state established # 특정 포트로 들어온 연결 확인 ss -tnp '( dport = :80 or sport = :80 )' # 소켓 상태별 개수 요약 (빠른 전체 현황 파악) ss -s # unix 도메인 소켓 포함 전체 ss -a # 특정 프로세스의 소켓만 (pid 기준) ss -p | grep pid=1234
`ss -s` 출력 예시 — 소켓 상태별 총 개수를 요약해 비정상적인 연결 급증을 파악합니다:
Total: 156 TCP: 45 (estab 12, closed 18, orphaned 0, timewait 15) Transport Total IP IPv6 RAW 0 0 0 UDP 8 5 3 TCP 27 15 12 INET 35 20 15 FRAG 0 0 0
이 요약에서 timewait가 비정상적으로 많으면 단시간에 연결이 폭증했다는 신호이고, estab(ESTABLISHED) 수가 예상보다 많으면 연결 누수(connection leak)를 의심해야 합니다.
netstat은 오랫동안 네트워크 진단의 표준 도구였지만, 현재는 공식적으로 deprecated 처리된 net-tools 패키지에 포함되어 있습니다. 현대 Linux 배포판(RHEL 8+, Ubuntu 20.04+)에서는 기본 설치되지 않습니다.
왜 ss가 더 나은가 — netstat과 ss를 성능, 정확성, 지원 측면에서 비교합니다:
| 비교 항목 | netstat |
ss |
|---|---|---|
| 데이터 소스 | /proc/net/tcp 파일 파싱 |
Netlink 소켓 (커널 직접 통신) |
| 속도 | 느림 (연결 수가 많을수록 체감) | 빠름 (수만 개 연결도 즉시) |
| 기본 설치 | RHEL8+에서 없음, 별도 설치 필요 | iproute2에 포함, 항상 있음 |
| 필터링 기능 | 제한적 | 강력한 필터 표현식 지원 |
| 유지보수 | 사실상 중단 | 활발히 개발 중 |
명령어 대응표 (마이그레이션 가이드) — netstat 명령어를 ss 명령어로 대체하는 치환 목록입니다:
bash# [구버전] netstat -tlnp → [신버전] ss -tlnp # [구버전] netstat -an → [신버전] ss -an # [구버전] netstat -s → [신버전] ss -s # [구버전] netstat -rn → [신버전] ip route show # [구버전] netstat -i → [신버전] ip -s link
그래도 netstat을 써야 한다면 (레거시 환경) — 구형 서버에서 net-tools 설치 후 netstat을 사용하는 방법입니다:
bash# netstat이 설치되어 있다면 netstat -tlnp # TCP LISTEN 포트와 프로세스 netstat -an # 모든 연결 상태 # netstat 없을 때 설치 # RHEL/CentOS: sudo dnf install net-tools # Ubuntu/Debian: sudo apt install net-tools
실전 팁: 스크립트나 자동화 코드를 작성할 때는 반드시 ss를 사용하세요. netstat은 새 서버에 설치되어 있지 않을 수 있으며, 이로 인해 스크립트가 실패할 수 있습니다.
nc (netcat)는 "네트워크의 스위스 아미 나이프"라고 불립니다. TCP/UDP 연결을 원시 수준에서 다룰 수 있어 포트 확인, 간단한 서버 에뮬레이션, 데이터 전송 등 다양한 용도로 사용합니다.
기본 포트 열림 확인 (`-zv` 옵션) — -zv로 포트가 열려 있는지 빠르게 확인합니다:
bash# -z: 데이터 전송 없이 포트만 스캔 (Zero-I/O mode) # -v: 자세한 출력 (verbose) nc -zv 192.168.1.20 5432 # 성공 시 출력: # Connection to 192.168.1.20 5432 port [tcp/postgresql] succeeded! # 실패 시 출력: # nc: connect to 192.168.1.20 port 5432 (tcp) failed: Connection refused
타임아웃 설정 (방화벽 차단 환경에서 무한 대기 방지) — 방화벽 DROP 상황에서 무한 대기하지 않도록 타임아웃을 설정합니다:
bash# -w 5: 5초 안에 응답 없으면 포기 nc -zv -w 5 192.168.1.20 5432 # 여러 포트 범위 스캔 nc -zv 192.168.1.20 8080-8090
UDP 포트 확인 — UDP는 연결 지향이 아니므로 nc로 데이터그램을 보내 응답을 확인합니다:
bash# -u: UDP 모드 nc -zuv 192.168.1.20 53
간단한 TCP 서버 테스트 (에코 서버 만들기) — nc로 임시 TCP 서버를 만들어 클라이언트 연결과 데이터 송수신을 테스트합니다:
bash# 터미널 1: 서버 역할 (9999번 포트에서 수신) # -l: listen 모드 nc -l 9999 # 터미널 2: 클라이언트로 접속 nc localhost 9999 안녕하세요 # → 터미널 1에 "안녕하세요"가 출력됨
이 방법으로 방화벽 없이 특정 포트가 "열릴 수 있는지" 테스트하거나, 애플리케이션 없이 TCP 연결 자체를 검증할 수 있습니다.
HTTP 요청을 수동으로 보내기 — nc로 HTTP 요청을 직접 작성해 보내면 서버 응답을 raw로 확인할 수 있습니다:
bash# nc로 직접 HTTP GET 요청 전송 printf "GET / HTTP/1.0\r\nHost: example.com\r\n\r\n" | nc example.com 80 # 출력 예시: # HTTP/1.1 200 OK # Content-Type: text/html # ...
파일 전송 (네트워크 복사) — nc로 파일을 네트워크로 전송하는 간단한 방법입니다:
bash# 수신 측 (서버): nc -l 9999 > received_file.tar.gz # 송신 측 (클라이언트): nc 192.168.1.20 9999 < backup.tar.gz # 전송 완료 후 자동 종료하려면 pv나 dd와 조합
nc 설치 확인 및 버전별 차이 — Linux 배포판마다 nc 패키지가 다르며 옵션도 일부 다릅니다:
bash# nc 버전 확인 (GNU netcat vs OpenBSD netcat) nc --version 2>&1 || nc -h 2>&1 | head -3 # RHEL/CentOS (nmap-ncat 패키지): sudo dnf install nmap-ncat # Ubuntu/Debian: sudo apt install netcat-openbsd
주의: GNU netcat과 OpenBSD netcat은 일부 옵션이 다릅니다.
-z옵션은 OpenBSD 버전에서 지원되며, 현대 배포판 대부분에서 기본 제공됩니다.
telnet으로 포트 확인:
telnet은 오래된 도구지만 포트 열림 확인 용도로 여전히 많이 쓰입니다. 특히 nc가 없는 환경에서 유용합니다.
bash# 기본 사용법 telnet 192.168.1.20 5432 # 성공 시 (PostgreSQL): # Trying 192.168.1.20... # Connected to 192.168.1.20. # Escape character is '^]'. # (PostgreSQL 배너 메시지 출력) # 실패 시 (Connection refused): # Trying 192.168.1.20... # telnet: connect to address 192.168.1.20: Connection refused # telnet 종료: Ctrl+] 후 quit 입력
telnet vs nc 비교 — 두 도구의 특징을 비교해 상황에 맞게 선택합니다:
| 항목 | telnet | nc |
|---|---|---|
| 타임아웃 설정 | 없음 (직접 설정 불가) | -w 옵션으로 설정 가능 |
| UDP 지원 | 불가 | 가능 (-u) |
| 스크립트 활용 | 어려움 | 쉬움 (종료 코드 반환) |
| 설치 여부 | 보안상 기본 제외 경우 많음 | 더 범용적 |
lsof -i — 포트를 점유한 프로세스 찾기:
lsof는 List Open Files의 약자로, Linux에서 "모든 것은 파일"이라는 철학에 따라 소켓도 파일로 취급합니다.
bash# 모든 네트워크 연결 표시 sudo lsof -i # 특정 포트를 사용하는 프로세스 sudo lsof -i :8080 # 특정 프로토콜과 포트 sudo lsof -i tcp:5432 # 특정 IP 주소와의 연결 sudo lsof -i @192.168.1.20 # LISTEN 상태만 (포트 바인딩 확인) sudo lsof -i -s TCP:LISTEN # 출력 예시: # COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME # nginx 3456 root 6u IPv4 28374 0t0 TCP *:http (LISTEN) # postgres 2345 postgres 5u IPv4 27891 0t0 TCP localhost:postgresql (LISTEN) # java 4567 tomcat 21u IPv6 29234 0t0 TCP *:8080 (LISTEN)
lsof vs ss 비교 — 열린 포트와 프로세스 연결을 확인하는 두 도구의 출력 차이입니다:
bash# 포트 8080을 사용 중인 프로세스 찾기 (두 방법 비교) sudo lsof -i :8080 sudo ss -tlnp | grep :8080 # ss가 더 빠르고 정보가 많지만, lsof는 fd(파일 디스크립터) 정보까지 제공
curl로 HTTP/HTTPS 응답 확인 — curl로 HTTP 상태 코드와 응답 헤더를 빠르게 확인합니다:
bash# 기본 HTTP GET (응답 헤더 포함) curl -v http://localhost:8080/health # 응답 코드만 확인 (스크립트에서 유용) curl -s -o /dev/null -w "%{http_code}" http://localhost:8080/health # 출력: 200 # 타임아웃 설정 (연결 3초, 전체 5초) curl --connect-timeout 3 --max-time 5 http://192.168.1.20:8080/api/v1/ping # HTTPS 인증서 무시 (개발 환경) curl -k https://localhost:8443/health # JSON POST 요청 curl -X POST \ -H "Content-Type: application/json" \ -d '{"user":"test","pass":"1234"}' \ http://localhost:3001/auth/login # 응답 헤더만 확인 (HEAD 요청) curl -I http://localhost:8080/ # 자세한 연결 타이밍 정보 curl -w "\n연결: %{time_connect}s\nTLS: %{time_appconnect}s\n응답: %{time_starttransfer}s\n전체: %{time_total}s\n" \ -o /dev/null -s http://localhost:8080/
curl 응답 코드 해석 — HTTP 상태 코드별 의미와 가능한 원인을 정리했습니다:
| HTTP 코드 | 의미 | 가능한 원인 |
|---|---|---|
| 200 | 정상 | - |
| 301/302 | 리다이렉트 | URL 변경 |
| 401 | 인증 필요 | 토큰/자격증명 확인 |
| 403 | 접근 거부 | 권한 설정 확인 |
| 404 | 리소스 없음 | 경로(PATH) 오류 |
| 500 | 서버 내부 오류 | 애플리케이션 로그 확인 |
| 502 | 게이트웨이 오류 | upstream 서비스 다운 |
| 503 | 서비스 불가 | 서버 과부하 또는 다운 |
서비스를 시작할 때 가장 흔하게 만나는 오류 중 하나가 Address already in use입니다. 이는 해당 포트를 이미 다른 프로세스가 사용하고 있다는 의미입니다.
오류 상황 재현 및 증상 — 포트 충돌이 발생했을 때 나타나는 에러 메시지를 확인합니다:
bash# Node.js 앱 시작 시 node app.js # Error: listen EADDRINUSE: address already in use :::3000 # Java Spring Boot 시작 시 java -jar myapp.jar # Web server failed to start. Port 8080 was already in use. # Python uvicorn 시작 시 uvicorn main:app --port 8000 # ERROR: [Errno 98] Address already in use
단계별 해결 방법 — 포트를 점유한 프로세스를 찾고 종료하거나 포트를 변경합니다:
bash# 1단계: 해당 포트를 사용 중인 프로세스 찾기 # 방법 A: ss 사용 (권장) sudo ss -tlnp | grep :8080 # 방법 B: lsof 사용 sudo lsof -i :8080 # 방법 C: fuser 사용 sudo fuser 8080/tcp # 출력 예시 (ss): # tcp LISTEN 0 511 0.0.0.0:8080 0.0.0.0:* users:(("java",pid=4567,fd=21)) # 2단계: 프로세스 정체 파악 ps aux | grep 4567 # → java 프로세스가 이미 실행 중인 것 확인 # 3단계-A: 기존 프로세스 종료 (정상 종료 먼저) kill 4567 # 3단계-B: 정상 종료 안 될 때 강제 종료 kill -9 4567 # 3단계-C: 프로세스 이름으로 한 번에 종료 pkill -f "java.*myapp.jar" # 4단계: 포트가 해제되었는지 확인 sudo ss -tlnp | grep :8080 # 아무것도 출력되지 않으면 성공 # 5단계: 서비스 재시작 sudo systemctl start myapp
TIME_WAIT로 인한 포트 사용 불가 문제 — 재시작 직후 TIME_WAIT 상태 소켓이 포트를 잡고 있으면 바인딩이 실패합니다:
bash# 서비스를 재시작했는데도 포트가 안 열릴 때 sudo ss -tnp | grep :8080 | grep TIME_WAIT # → TIME_WAIT 상태의 소켓이 포트를 잠시 점유 중 # 해결책 1: 잠시 기다리기 (TIME_WAIT는 약 60초 후 자동 해제) # 해결책 2: SO_REUSEADDR 옵션 (애플리케이션 설정) # Node.js 예시: # server.listen({ port: 8080, exclusive: false }, callback) # 해결책 3: 커널 파라미터 조정 (서버 재사용 시간 단축) sudo sysctl net.ipv4.tcp_tw_reuse=1
스크립트로 포트 상태 자동 확인 — 여러 포트를 한 번에 점검하는 자동화 스크립트입니다:
bash#!/bin/bash PORT=${1:-8080} PID=$(sudo ss -tlnp | grep ":${PORT}" | awk '{print $NF}' | grep -oP 'pid=\K[0-9]+') if [ -z "$PID" ]; then echo "포트 ${PORT}: 사용 가능" else echo "포트 ${PORT}: PID ${PID}가 사용 중" ps -p "$PID" -o pid,comm,args --no-headers fi
tcpdump는 네트워크 인터페이스를 지나는 패킷을 실시간으로 캡처하고 분석하는 도구입니다. 다른 도구로 해결이 안 되는 문제를 패킷 레벨에서 확인할 때 사용합니다.
기본 사용법 — tcpdump의 기본 옵션으로 네트워크 인터페이스의 패킷을 캡처합니다:
bash# 모든 인터페이스에서 캡처 (root 권한 필요) sudo tcpdump # 특정 인터페이스에서 캡처 sudo tcpdump -i eth0 # 인터페이스 목록 확인 sudo tcpdump -D
포트 기반 필터링 (가장 많이 쓰는 패턴) — 특정 포트의 트래픽만 캡처해 연결 문제를 분석합니다:
bash# 특정 포트의 패킷만 캡처 sudo tcpdump -i eth0 port 5432 # 출력 예시: # 14:32:01.234567 IP 10.0.1.5.52341 > 10.0.1.20.5432: Flags [S], seq 1234567890, win 64240, length 0 # 14:32:01.234890 IP 10.0.1.20.5432 > 10.0.1.5.52341: Flags [S.], seq 987654321, ack 1234567891, win 65160, length 0 # 14:32:01.235001 IP 10.0.1.5.52341 > 10.0.1.20.5432: Flags [.], ack 1, win 502, length 0 # → 위 세 줄이 3-Way Handshake (SYN, SYN-ACK, ACK) # TCP Flags 해석: # [S] = SYN # [S.] = SYN-ACK # [.] = ACK # [P.] = PSH+ACK (데이터 전송) # [F.] = FIN+ACK (연결 종료 시작) # [R] = RST (연결 강제 리셋 — Connection refused의 원인)
특정 호스트 + 포트 조합 필터 — 서버 간 특정 트래픽을 정확히 잡아내는 필터 조합입니다:
bash# 특정 호스트와의 특정 포트 통신만 캡처 sudo tcpdump -i eth0 host 192.168.1.20 and port 5432 # 특정 출발지에서 오는 패킷만 sudo tcpdump -i eth0 src 192.168.1.10 and port 80 # HTTP 트래픽 캡처 (80 또는 8080) sudo tcpdump -i eth0 'port 80 or port 8080'
파일로 저장 후 분석 (Wireshark 연동) — 캡처 결과를 pcap 파일로 저장해 Wireshark에서 분석합니다:
bash# pcap 파일로 저장 (-w) sudo tcpdump -i eth0 port 5432 -w /tmp/db-traffic.pcap # 저장된 파일 읽기 (-r) sudo tcpdump -r /tmp/db-traffic.pcap # Wireshark로 분석 (로컬 GUI 환경) wireshark /tmp/db-traffic.pcap
패킷 내용까지 보기 — -A나 -X로 패킷 페이로드를 ASCII나 hex로 확인합니다:
bash# -A: ASCII로 페이로드 출력 (HTTP 요청/응답 내용 확인) sudo tcpdump -i eth0 -A port 80 | head -50 # -X: HEX + ASCII 동시 출력 sudo tcpdump -i eth0 -X port 443 # 캡처 패킷 수 제한 (-c) sudo tcpdump -i eth0 port 5432 -c 100
실전 시나리오: DB 연결 패킷 추적 — 애플리케이션 서버에서 DB 연결 실패를 tcpdump로 패킷 레벨에서 추적합니다:
bash# 터미널 1: 패킷 캡처 시작 sudo tcpdump -i any port 5432 -n # 터미널 2: DB 연결 시도 psql -h 192.168.1.20 -U myuser -d mydb # 터미널 1에서 확인: # - SYN만 보이고 SYN-ACK가 없다 → 방화벽 DROP (Connection timed out) # - RST가 바로 온다 → 포트 닫힘 (Connection refused) # - 3-Way Handshake 완료 후 RST → 인증 실패 # - 3-Way Handshake 완료 후 정상 데이터 → L7 레이어 문제
상황 — 개발자 PC(192.168.1.10)에서 DB 서버(192.168.1.20:5432, PostgreSQL)로 접속이 안 됩니다. 1분 안에 원인 계층을 특정합니다.
원인 — 소켓 오류 유형으로 계층을 구분합니다: Connection refused = 서비스 미실행 또는 포트 바인딩 문제 / Connection timed out = 방화벽 DROP.
진단 — ping → nc → ss 순서로 계층을 좁힙니다:
해결 — 계층별 체크:
STEP 1 — 네트워크 도달 가능성 확인 (10초)
bash# 개발자 PC에서 실행 ping -c 3 192.168.1.20 # 성공: 네트워크 레이어(L3)는 정상 # 실패: IP 주소 오타, 라우팅 문제, 서버 다운
STEP 2 — 포트 연결 확인 (10초) — nc나 telnet으로 DB 포트가 열려 있는지 확인합니다:
bash# 개발자 PC에서 실행 (5초 타임아웃) nc -zv -w 5 192.168.1.20 5432 # 결과 A: Connection refused # → 서비스 다운 또는 서버 로컬 방화벽 REJECT # → STEP 3A로 이동 # 결과 B: Connection timed out (5초 후 실패) # → 네트워크/클라우드 방화벽이 DROP 중 # → STEP 3B로 이동 # 결과 C: Connected! # → TCP는 OK, 인증/권한 문제 가능성 # → STEP 4로 이동
STEP 3A — DB 서버에서 서비스 상태 확인 — DB 서버에서 직접 서비스 동작 여부와 포트 바인딩을 확인합니다:
bash# DB 서버에서 실행 # PostgreSQL이 실제로 실행 중인가? sudo systemctl status postgresql # 어떤 포트에서 듣고 있는가? sudo ss -tlnp | grep postgres # 출력: tcp LISTEN 127.0.0.1:5432 → 로컬만 바인딩! 외부 접근 불가 # 해결: PostgreSQL 설정 변경 후 재시작 # /etc/postgresql/14/main/postgresql.conf # listen_addresses = '*' # 또는 특정 IP sudo systemctl restart postgresql # pg_hba.conf도 확인 (클라이언트 인증 허용 설정) sudo cat /etc/postgresql/14/main/pg_hba.conf | grep -v "^#" | grep -v "^$"
STEP 3B — 방화벽 규칙 확인 — DB 서버의 방화벽이 클라이언트 IP에서 오는 트래픽을 허용하는지 확인합니다:
bash# DB 서버에서 실행 # firewalld 사용 중인 경우 (RHEL/CentOS) sudo firewall-cmd --list-ports sudo firewall-cmd --list-services # iptables 직접 확인 sudo iptables -L INPUT -n -v | grep 5432 # 포트 허용 추가 (firewalld) sudo firewall-cmd --permanent --add-port=5432/tcp sudo firewall-cmd --reload # 클라우드 환경이면 콘솔에서 보안 그룹(Security Group) 확인 필요 # AWS: EC2 → 보안 그룹 → 인바운드 규칙 → 5432/TCP 허용 여부
STEP 4 — 인증 및 DB 레벨 확인 — 네트워크는 정상인데 연결이 안 되면 DB 계정 권한을 확인합니다:
bash# 개발자 PC에서 psql -h 192.168.1.20 -U myuser -d mydb -W # 오류 메시지 별 원인: # "password authentication failed" → 비밀번호 오류 # "database does not exist" → DB 이름 오류 # "role does not exist" → 사용자 이름 오류 # "no pg_hba.conf entry" → pg_hba.conf 설정 필요 # 연결 문자열 확인 (.env 파일) cat .env | grep DATABASE_URL # DATABASE_URL=postgres://myuser:mypass@192.168.1.20:5432/mydb
빠른 요약 판단표 — nc와 ping 결과 조합으로 장애 원인을 빠르게 분류합니다:
| nc 결과 | ping 결과 | 원인 | 해결 방법 |
|---|---|---|---|
| refused | 성공 | 서비스 미실행 / 바인딩 오류 | systemctl start, listen_addresses 확인 |
| timeout | 성공 | 방화벽 DROP | 방화벽 규칙 추가 |
| timeout | 실패 | 네트워크 단절 | 라우팅, VPN, 서버 상태 확인 |
| connected | - | L7(인증/DB) 문제 | 사용자/비밀번호/DB명 확인 |
상황 — 서비스가 시작되지 않습니다. 포트 충돌 또는 권한 문제가 원인입니다.
원인 — EADDRINUSE: 해당 포트를 이미 다른 프로세스가 점유 중 / PermissionError: 비루트 프로세스가 1024 미만 포트를 바인드 시도.
진단 — 오류 메시지로 유형을 구분합니다:
시나리오 A: 포트 충돌 (EADDRINUSE)
bash# 증상: Node.js 앱 시작 시 node server.js # Error: listen EADDRINUSE: address already in use :::3000 # 진단 1: 누가 3000번 포트를 쓰고 있는가? sudo ss -tlnp | grep :3000 # tcp LISTEN 0 128 0.0.0.0:3000 0.0.0.0:* users:(("node",pid=7890,fd=12)) # 진단 2: 해당 프로세스 정체 파악 ps aux | grep 7890 # node 7890 0.5 2.3 /usr/bin/node /opt/old-app/server.js # 해결 1: 이전 앱 인스턴스가 종료 안 된 경우 → 종료 kill 7890 # 또는 pkill -f "node /opt/old-app/server.js" # 해결 2: 포트를 변경해야 하는 경우 # .env 파일에서 PORT=3001로 변경 # 해결 3: systemd로 관리되는 서비스면 sudo systemctl stop old-app sudo systemctl start new-app
시나리오 B: 1024 이하 포트 권한 오류 (PermissionError)
bash# 증상: nginx나 앱이 80번 포트를 열려 할 때 sudo python3 -m http.server 80 # PermissionError: [Errno 13] Permission denied # 해결 1: sudo로 실행 (권장하지 않음, 보안 위험) sudo python3 -m http.server 80 # 해결 2: CAP_NET_BIND_SERVICE 권한 부여 (권장) sudo setcap cap_net_bind_service=+ep /usr/bin/python3 # 해결 3: systemd 유닛 파일에서 설정 # /etc/systemd/system/myapp.service # [Service] # AmbientCapabilities=CAP_NET_BIND_SERVICE # User=myapp # 해결 4: 높은 포트(8080)로 실행 후 iptables로 포워딩 sudo iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-port 8080
시나리오 C: SELinux 포트 바인딩 차단 (RHEL/CentOS)
bash# 증상: 서비스 설정은 완벽한데 포트가 안 열림 # SELinux 감사 로그 확인 sudo ausearch -m avc -ts recent | grep bind # SELinux 허용 포트 목록 확인 sudo semanage port -l | grep http # 커스텀 포트 허용 추가 sudo semanage port -a -t http_port_t -p tcp 8081 # 임시 SELinux 비활성화 (테스트용만, 운영 금지) sudo setenforce 0 # (영구 적용은 /etc/selinux/config 수정)
상황 — 서비스가 점점 느려지다가 결국 "too many open files" 오류와 함께 멈춥니다. ss -s로 확인하면 CLOSE_WAIT 소켓이 수천 개 쌓여 있습니다.
원인 — CLOSE_WAIT은 상대방이 TCP FIN을 보냈는데 우리 애플리케이션이 소켓을 닫지 않은 상태입니다. 코드에서 HTTP client나 DB connection을 close()/finally 블록에서 명시적으로 닫지 않을 때 발생합니다.
진단
bash# CLOSE_WAIT 상태 소켓 개수 확인 ss -tn state close-wait | wc -l # 출력: 247 (정상은 0~소수) # 어떤 프로세스의 소켓인지 확인 ss -tnp state close-wait | head -20 # tcp CLOSE-WAIT 1 0 10.0.1.5:8080 10.0.1.10:54321 users:(("java",pid=4567,fd=43)) # tcp CLOSE-WAIT 1 0 10.0.1.5:8080 10.0.1.10:54322 users:(("java",pid=4567,fd=44)) # ... # 파일 디스크립터 현황 확인 sudo lsof -p 4567 | wc -l # 출력: 1024 (fd 한도에 근접!) # fd 한도 확인 sudo cat /proc/4567/limits | grep "open files" # Max open files 1024 4096 files
원인 이해 — TCP 종료 4-way handshake에서 TIME_WAIT이 발생하는 과정을 시각화합니다:
클라이언트가 연결을 끊음 (FIN 전송) ↓ 서버 OS: FIN-ACK 응답 → 상태: CLOSE_WAIT ↓ 서버 앱: close()를 호출해야 하는데 안 함! ↓ 소켓이 CLOSE_WAIT 상태로 영원히 남음
CLOSE_WAIT는 "상대방이 연결을 끊었는데 내 애플리케이션이 소켓을 아직 반환하지 않은" 상태입니다. 애플리케이션 코드에서 커넥션 풀 반환이나 소켓 close()를 누락한 버그가 원인입니다.
단기 해결 (임시) — sysctl로 TIME_WAIT 재사용을 활성화해 즉시 포트를 재사용합니다:
bash# 해당 프로세스 재시작 (소켓 강제 해제) sudo systemctl restart myapp-java # 재시작 후 확인 ss -tn state close-wait | wc -l # 출력: 0
근본 해결 (코드 레벨) — SO_REUSEADDR 소켓 옵션 설정이나 연결 풀 조정으로 근본 원인을 해결합니다:
bash# Java 코드 예시: try-with-resources로 소켓 자동 반환 # try (Connection conn = dataSource.getConnection()) { # // 작업 # } // 자동으로 conn.close() 호출 # Python 코드 예시: with 문 사용 # with socket.create_connection((host, port)) as sock: # # 작업 # # 자동으로 sock.close() 호출 # Node.js: response.destroy() 또는 이벤트 리스너 정리 확인 # 커넥션 풀 설정 확인 (Java HikariCP 예시) # maximumPoolSize=10 # connectionTimeout=30000 # keepaliveTime=60000
모니터링 설정 (재발 방지) — TIME_WAIT 소켓 수를 지속적으로 모니터링해 임계치 초과 시 알림을 받습니다:
bash# cron으로 주기적 감지 echo "*/5 * * * * root ss -tn state close-wait | wc -l >> /var/log/close_wait.log" \ | sudo tee /etc/cron.d/check-close-wait # 알람 임계값 초과 시 Slack 알림 (스크립트 예시) COUNT=$(ss -tn state close-wait | wc -l) if [ "$COUNT" -gt 100 ]; then curl -X POST -H 'Content-type: application/json' \ --data "{\"text\":\"경고: CLOSE_WAIT 소켓 ${COUNT}개 감지!\"}" \ "$SLACK_WEBHOOK_URL" fi
실제 현업에서 겪는 상황을 재현한 체계적인 대응 가이드입니다. 이 체크리스트를 사용하면 대부분의 DB 연결 문제를 1분 이내에 원인을 특정할 수 있습니다.
상황: 신규 배포 후 개발자에게 슬랙 메시지가 옴
"배포 후부터 DB가 안 붙어요. 로컬에서는 됐는데 스테이징 서버에서 안 돼요."
진단 커맨드 시퀀스 (복사해서 바로 실행) — 포트 문제 발생 시 즉시 실행하는 진단 명령어 시퀀스입니다:
bash# ============================================ # DB 연결 문제 1분 진단 체크리스트 # DB_HOST, DB_PORT를 실제 값으로 교체하세요 # ============================================ DB_HOST="192.168.1.20" DB_PORT="5432" echo "=== 1. 네트워크 도달성 확인 ===" ping -c 2 -W 2 "$DB_HOST" && echo "OK: ping 성공" || echo "FAIL: ping 실패 → 네트워크/서버 문제" echo "" echo "=== 2. 포트 열림 확인 ===" nc -zv -w 5 "$DB_HOST" "$DB_PORT" 2>&1 # refused → 서비스 문제, timeout → 방화벽 문제, connected → 인증 문제 echo "" echo "=== 3. 현재 서버의 포트 바인딩 확인 (DB 서버에서 실행) ===" sudo ss -tlnp | grep ":${DB_PORT}" echo "" echo "=== 4. DB 서비스 상태 (DB 서버에서 실행) ===" sudo systemctl status postgresql --no-pager | head -20 echo "" echo "=== 5. 방화벽 규칙 확인 (DB 서버에서 실행) ===" sudo firewall-cmd --list-ports 2>/dev/null || sudo iptables -L INPUT -n | grep "$DB_PORT"
가장 흔한 원인 TOP 5 (경험 기반) — 현장에서 가장 자주 만나는 포트 문제 원인과 확인 방법입니다:
| 순위 | 원인 | 확인 명령 | 해결 방법 |
|---|---|---|---|
| 1위 | 환경변수 오류 (잘못된 HOST/PORT) | env | grep DB |
.env 파일 또는 k8s ConfigMap 수정 |
| 2위 | DB가 로컬 바인딩 (127.0.0.1) |
ss -tlnp | grep 5432 |
listen_addresses='*' 설정 |
| 3위 | 방화벽/보안그룹 미허용 | nc -zv DB_HOST 5432 |
인바운드 규칙에 포트 추가 |
| 4위 | DB 서비스 미실행 | systemctl status postgresql |
systemctl start postgresql |
| 5위 | pg_hba.conf 인증 설정 누락 | tail /var/log/postgresql/*.log |
pg_hba.conf에 클라이언트 IP 추가 |
Docker/Kubernetes 환경에서 추가 확인 — 컨테이너 환경에서는 호스트 포트 외에 컨테이너 내부 포트도 함께 확인해야 합니다:
bash# Docker: 컨테이너 내부에서 DB 접속 확인 docker exec -it app-container sh nc -zv db-service 5432 # Kubernetes: Pod에서 Service로 접속 확인 kubectl exec -it app-pod -- sh nc -zv db-service.default.svc.cluster.local 5432 # K8s Service 설정 확인 kubectl get service db-service -o yaml kubectl get endpoints db-service # Pod 환경변수 확인 kubectl exec app-pod -- env | grep DB # 로그 확인 kubectl logs app-pod --tail=50 | grep -i "connect\|error\|failed"
연결은 되는데 쿼리가 느린 경우 — 포트는 열려 있지만 응답이 느릴 때 DB나 앱 서버 부하를 확인합니다:
bash# 현재 DB 연결 수 확인 (PostgreSQL) psql -h "$DB_HOST" -U postgres -c "SELECT count(*) FROM pg_stat_activity;" # 연결별 상태 확인 psql -h "$DB_HOST" -U postgres -c \ "SELECT state, count(*) FROM pg_stat_activity GROUP BY state;" # 오래 실행 중인 쿼리 찾기 psql -h "$DB_HOST" -U postgres -c \ "SELECT pid, now() - query_start AS duration, query FROM pg_stat_activity WHERE state = 'active' AND now() - query_start > interval '5 seconds' ORDER BY duration DESC;"
배포 파이프라인에 포트 점검을 통합하면 "배포 후 서비스가 안 떠요" 같은 문제를 조기에 감지할 수 있습니다.
배포 후 헬스체크 스크립트 — 새 버전 배포 후 서비스 포트가 정상적으로 열렸는지 자동 확인합니다:
bash#!/bin/bash # /opt/scripts/post-deploy-check.sh # 배포 직후 실행하여 서비스 정상 기동 여부를 빠르게 확인 set -e APP_HOST="localhost" declare -A SERVICES=( ["API Gateway"]="8080" ["Auth Service"]="3001" ["Catalog Service"]="3002" ["Cart Service"]="3003" ["Order Service"]="3004" ) FAILED=0 PASSED=0 echo "======================================" echo "배포 후 포트 점검 시작: $(date)" echo "======================================" for SERVICE_NAME in "${!SERVICES[@]}"; do PORT="${SERVICES[$SERVICE_NAME]}" # TCP 포트 연결 확인 (2초 타임아웃) if nc -zv -w 2 "$APP_HOST" "$PORT" 2>/dev/null; then echo "✓ ${SERVICE_NAME} (포트 ${PORT}): LISTENING" # HTTP 서비스라면 헬스 엔드포인트도 확인 if [[ "$PORT" =~ ^(8080|3001|3002|3004)$ ]]; then HTTP_CODE=$(curl -s -o /dev/null -w "%{http_code}" \ --connect-timeout 2 --max-time 5 \ "http://${APP_HOST}:${PORT}/health" 2>/dev/null || echo "000") if [[ "$HTTP_CODE" == "200" ]]; then echo " └─ HTTP 헬스체크: OK (${HTTP_CODE})" ((PASSED++)) else echo " └─ HTTP 헬스체크: FAIL (${HTTP_CODE})" ((FAILED++)) fi else ((PASSED++)) fi else echo "✗ ${SERVICE_NAME} (포트 ${PORT}): DOWN" ((FAILED++)) fi done echo "======================================" echo "결과: ${PASSED}개 정상, ${FAILED}개 실패" echo "======================================" if [ "$FAILED" -gt 0 ]; then echo "경고: 일부 서비스가 정상 기동되지 않았습니다." exit 1 fi exit 0
서비스 포트 모니터링 cron 설정 — cron으로 주기적으로 포트 상태를 확인하고 장애를 빠르게 감지합니다:
bash# /etc/cron.d/port-monitor # 5분마다 핵심 포트 모니터링 */5 * * * * root /opt/scripts/check-ports.sh >> /var/log/port-monitor.log 2>&1
check-ports.sh (경량 버전) — 외부 도구 없이 bash만으로 여러 포트를 모니터링하는 스크립트입니다:
bash#!/bin/bash TIMESTAMP=$(date '+%Y-%m-%d %H:%M:%S') PORTS=(8080 3001 3002 3003 3004 3005 3006 5432 6379) for PORT in "${PORTS[@]}"; do if ss -tlnp | grep -q ":${PORT}"; then echo "${TIMESTAMP} PORT ${PORT}: OK" else echo "${TIMESTAMP} PORT ${PORT}: DOWN" # 실제로는 여기서 Slack/PagerDuty 알림 전송 fi done
Prometheus + Alertmanager 연동 (고급) — Blackbox Exporter로 포트 상태를 Prometheus에서 수집하고 Alertmanager로 알림을 보냅니다:
bash# node_exporter가 있으면 포트 상태를 메트릭으로 수집 가능 # /etc/prometheus/rules/port-alerts.yml 예시: # groups: # - name: port-alerts # rules: # - alert: ServicePortDown # expr: up{job="myapp"} == 0 # for: 1m # labels: # severity: critical # annotations: # summary: "서비스 포트 다운: {{ $labels.instance }}" # description: "1분 이상 포트가 응답하지 않습니다." # 또는 blackbox_exporter로 TCP 포트 프로브 # - job_name: 'tcp-probes' # metrics_path: /probe # params: # module: [tcp_connect] # static_configs: # - targets: # - 'localhost:8080' # - 'localhost:5432'
실무 팁 — 자주 쓰는 진단 명령 별칭(alias) 설정 — 반복되는 긴 명령어를 alias로 줄여 빠르게 실행합니다:
bash# ~/.bashrc 또는 ~/.zshrc에 추가 alias ports='sudo ss -tulnp' alias port-who='f(){ sudo ss -tlnp | grep ":$1"; }; f' alias port-check='f(){ nc -zv -w 3 $1 $2 2>&1; }; f' alias conn-count='ss -tn state established | wc -l' alias timewait-count='ss -tn state time-wait | wc -l' # 사용 예: # ports → 모든 LISTEN 포트 한눈에 # port-who 8080 → 8080 포트를 쓰는 프로세스 # port-check 192.168.1.20 5432 → DB 포트 연결 확인 # conn-count → 현재 활성 연결 수
— — —
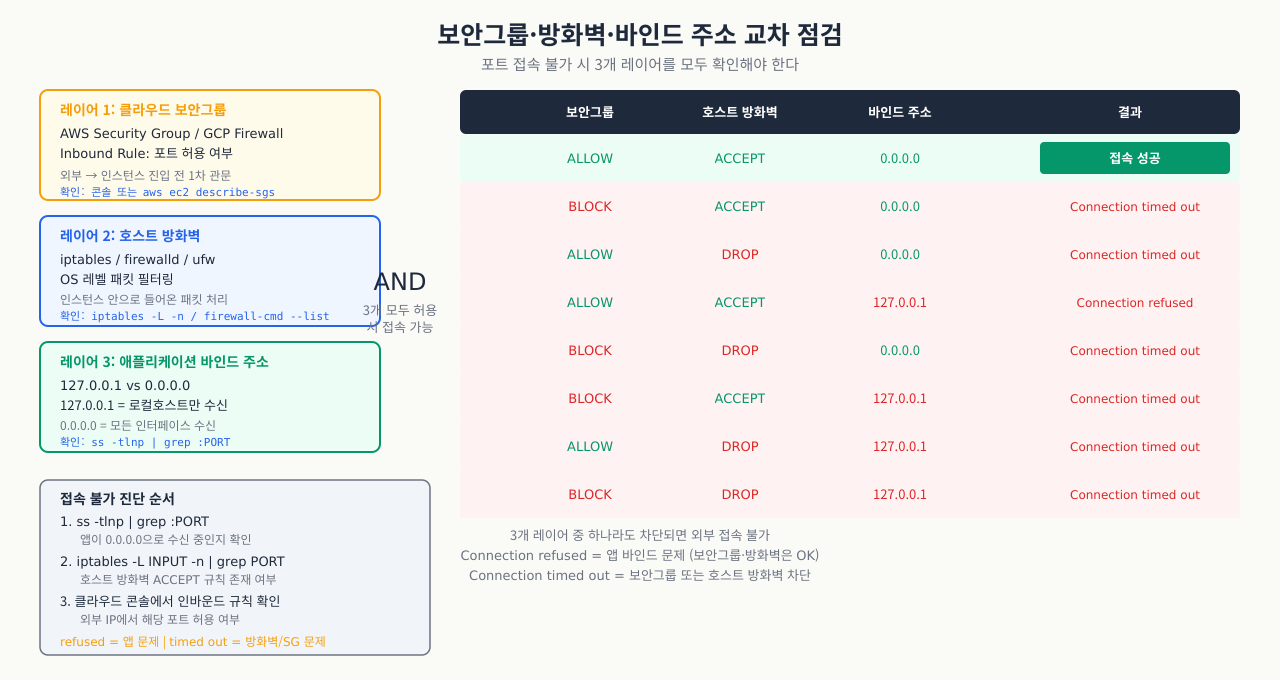
"포트를 열었는데 안 됩니다"의 원인은 여러 레이어에 있습니다. 순서대로 체크리스트를 따라가면 대부분 2분 안에 찾을 수 있습니다.
진단 플로우 — 포트 접속 실패 시 원인을 단계적으로 좁혀가는 결정 흐름도입니다:
클라이언트 → [1. 클라우드 보안그룹/NACL] → [2. OS 방화벽] → [3. 프로세스 리슨] → [4. 바인드 주소] → 서버
bash# 1단계: 서버에서 프로세스 리슨 확인 sudo ss -tlnp | grep :80 # LISTEN 0.0.0.0:80 → 외부 접속 가능 # LISTEN 127.0.0.1:80 → 루프백만! 외부 불가 (바인드 문제) # (없음) → 프로세스 미실행 # 2단계: OS 방화벽 확인 sudo firewall-cmd --list-all 2>/dev/null || sudo iptables -L -n | grep 80 # 3단계: 서버 자신에서 연결 테스트 curl -v http://localhost:80 # 로컬에서 성공? curl -v http://<서버IP>:80 # 외부 IP로 테스트 # 4단계: 원격에서 연결 테스트 (포트 열림 여부) nc -zv <서버IP> 80 # Connection succeeded or refused telnet <서버IP> 80 # 5단계: 클라우드 보안그룹 (AWS 예) aws ec2 describe-security-groups --group-ids sg-xxxx \ --query 'SecurityGroups[].IpPermissions'
바인드 주소 0.0.0.0 vs 127.0.0.1 — 어떤 주소에 바인드하느냐에 따라 외부 접근 가능 여부가 달라집니다:
| 바인드 주소 | 의미 | 외부 접속 |
|---|---|---|
0.0.0.0 |
모든 인터페이스 | 가능 |
127.0.0.1 |
로컬 루프백만 | 불가 |
192.168.1.100 |
특정 IP만 | 해당 IP로만 가능 |
:: (IPv6) |
모든 인터페이스 (IPv4 포함) | 가능 |
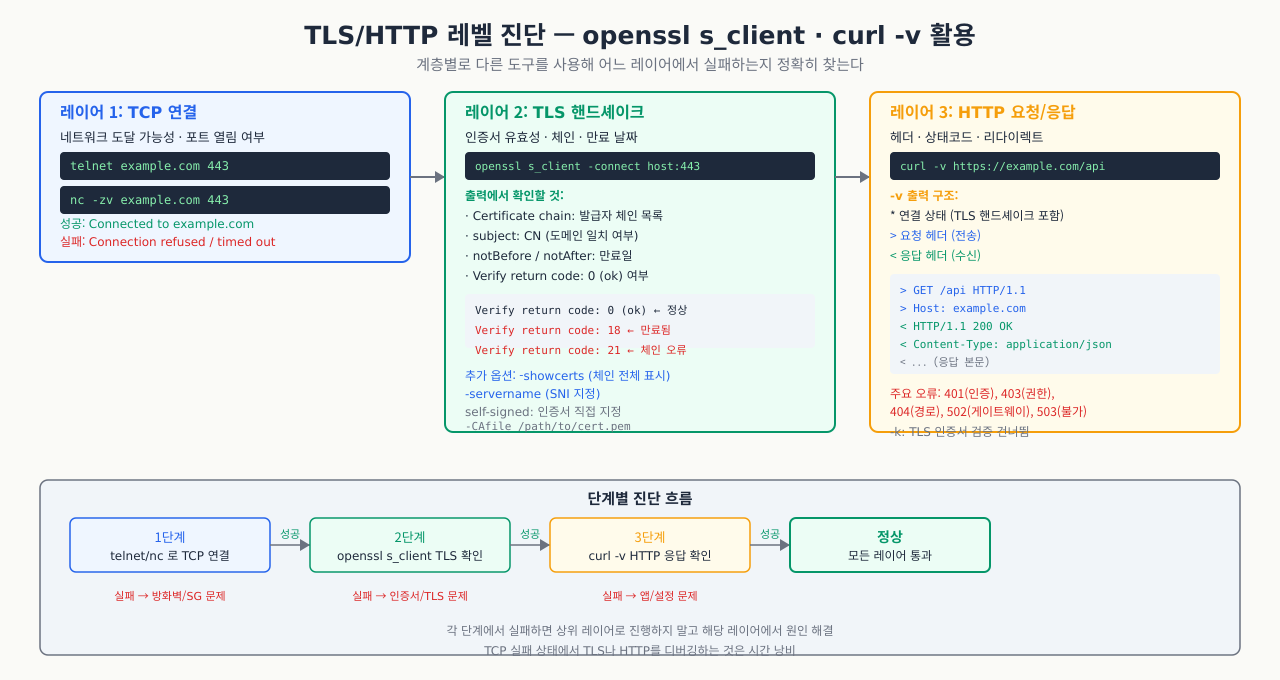
포트 443이 열려 있고 방화벽도 정상인데 HTTPS 접속이 안 됩니다. curl https://api.example.com을 실행하면 SSL certificate problem: certificate has expired나 SSL_ERROR_HANDSHAKE_FAILURE 같은 오류만 뜹니다. 포트 연결 자체는 성공했지만 그 위의 TLS 레이어에서 실패하는 경우, ping이나 telnet으로는 원인을 찾을 수 없습니다. openssl s_client와 curl -v가 TLS 핸드셰이크 과정을 단계별로 보여주므로, 인증서 만료인지 SNI 설정 오류인지 체인 누락인지 정확히 집어낼 수 있습니다.
포트는 열렸지만 TLS 핸드셰이크 실패, SNI 불일치, 인증서 오류 등으로 접속이 안 되는 경우 진단합니다.
openssl s_client — TLS 연결 상세 진단 — TLS 핸드셰이크 과정과 인증서 체인을 확인합니다:
bash# 기본 TLS 연결 테스트 openssl s_client -connect example.com:443 -servername example.com # 주요 출력 해석: # Certificate chain: 0~N개 인증서 체인 # subject: 서버 인증서 소유자 # issuer: 발급 기관 (CA) # Verify return code: 0 (ok) ← 0이 아니면 인증서 문제 # SNI(Server Name Indication) 명시적 지정 openssl s_client -connect 10.0.0.1:443 -servername api.example.com # IP로 접속하지만 SNI로 올바른 인증서를 선택 # 인증서 만료일 확인 echo | openssl s_client -connect example.com:443 -servername example.com 2>/dev/null | \ openssl x509 -noout -dates # notBefore=Apr 1 00:00:00 2025 GMT # notAfter=Apr 1 00:00:00 2026 GMT ← 만료일 확인 # TLS 버전 강제 지정 (구버전 지원 여부 확인) openssl s_client -connect example.com:443 -tls1_2 # TLS 1.2 openssl s_client -connect example.com:443 -tls1_3 # TLS 1.3
curl -v — HTTP 레벨 진단 — curl verbose 모드로 DNS → TCP → TLS → HTTP 각 단계를 추적합니다:
bash# 상세 연결 과정 확인 curl -v https://api.example.com/health 2>&1 | head -40 # 인증서 무시 (테스트용, 절대 운영 사용 금지) curl -k https://self-signed.example.com/ # SNI 헤더 확인 (리다이렉트 추적 포함) curl -v -L https://example.com 2>&1 | grep -E "< HTTP|SSL|TLS|Connected" # 특정 IP로 접속하면서 Host 헤더 지정 curl -v --resolve api.example.com:443:10.0.0.1 https://api.example.com/
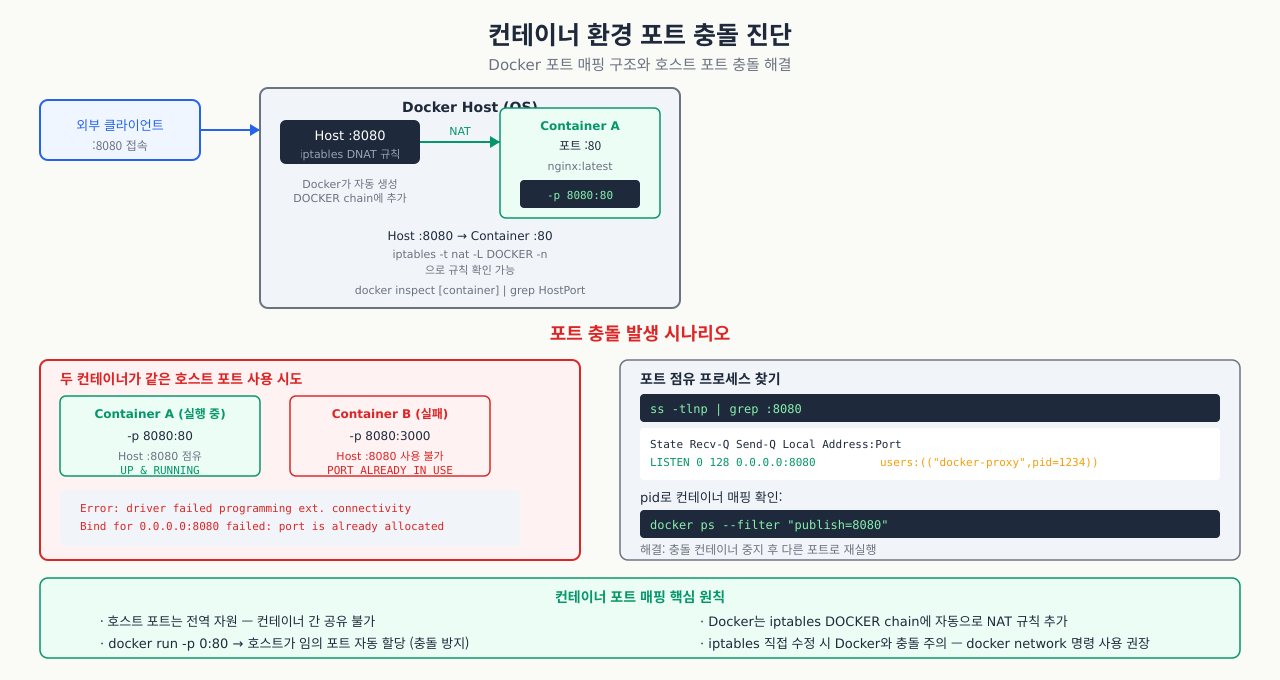
컨테이너를 올리려는데 "port is already allocated" 오류가 뜹니다. 그런데 ss -tlnp를 보면 호스트에서 그 포트를 쓰는 프로세스가 없습니다. 컨테이너 환경에서는 포트가 겹칠 수 있는 레이어가 세 개입니다: 호스트 프로세스, 실행 중인 다른 컨테이너, 그리고 종료됐지만 아직 정리되지 않은 컨테이너. docker ps가 보여주는 것과 호스트 ss가 보여주는 것이 다르기 때문에, 두 레이어를 모두 확인해야 원인을 찾을 수 있습니다.
Docker/컨테이너 환경에서는 포트가 중복될 수 있는 레이어가 많습니다.
포트 충돌 진단 — 같은 포트를 쓰는 프로세스가 있을 때 충돌 원인을 파악합니다:
bash# 호스트에서 점유 중인 포트 전체 확인 (Docker 포함) sudo ss -tlnp # 또는 (Docker 포트 매핑 포함) docker ps --format "table {{.Names}}\t{{.Ports}}" # 특정 포트를 사용 중인 컨테이너 찾기 docker ps | grep "0.0.0.0:80" # 컨테이너 내부에서 포트 확인 (컨테이너 네임스페이스) docker exec <container_id> ss -tlnp # 컨테이너 포트 매핑 상세 확인 docker inspect <container_id> | grep -A10 "PortBindings"
호스트 포트 vs 컨테이너 포트 개념 — Docker에서 -p 8080:80이 의미하는 포트 매핑 구조를 이해합니다:
호스트 80 → [Docker NAT (iptables DNAT)] → 컨테이너 내부 8080
bash# Docker가 추가한 iptables 규칙 확인 sudo iptables -t nat -L DOCKER -n | grep 80 # DNAT tcp 0.0.0.0/0 0.0.0.0/0 tcp dpt:80 to:172.17.0.2:8080 # 컨테이너 네임스페이스에서 직접 확인 (고급) CONTAINER_PID=$(docker inspect --format '{{.State.Pid}}' <container_id>) sudo nsenter -t $CONTAINER_PID -n ss -tlnp
다음 모듈에서는 SSH 심화 — 키 기반 인증, SSH 터널링, ProxyJump로 안전한 원격 접속과 포트 포워딩을 다룹니다.
'Linux' 카테고리의 다른 글
| [Linux] 서버 장애 초동 대응 — 5분 트리아지 (1) | 2026.05.23 |
|---|---|
| [Linux] SSH 고급 & 보안 하드닝 (0) | 2026.05.22 |
| [Linux] DNS & 이름 해석 트러블슈팅 (0) | 2026.05.22 |
| [Linux] 네트워킹 기초 (Networking Basics) (0) | 2026.05.22 |
| [Linux] 디스크 트러블슈팅 (0) | 2026.05.22 |