서버에 배포 직후 ping 93.184.216.34는 응답이 옵니다. 그런데 curl https://api.example.com을 실행하면 Could not resolve host: api.example.com이 뜨고 바로 실패합니다. 네트워크 자체는 정상인데 이름 해석이 안 되는 것입니다. /etc/resolv.conf를 열어보면 심볼릭 링크입니다.
DNS 해석이 실제로 어느 경로를 거치는지 알고 있으면, 어느 단계에서 끊겼는지 5분 안에 특정할 수 있습니다.
DNS & 이름 해석 트러블슈팅
which dig resolvectl || sudo apt-get install -y dnsutils
cat /etc/resolv.conf
systemctl is-active systemd-resolved
ls -la /etc/resolv.conf
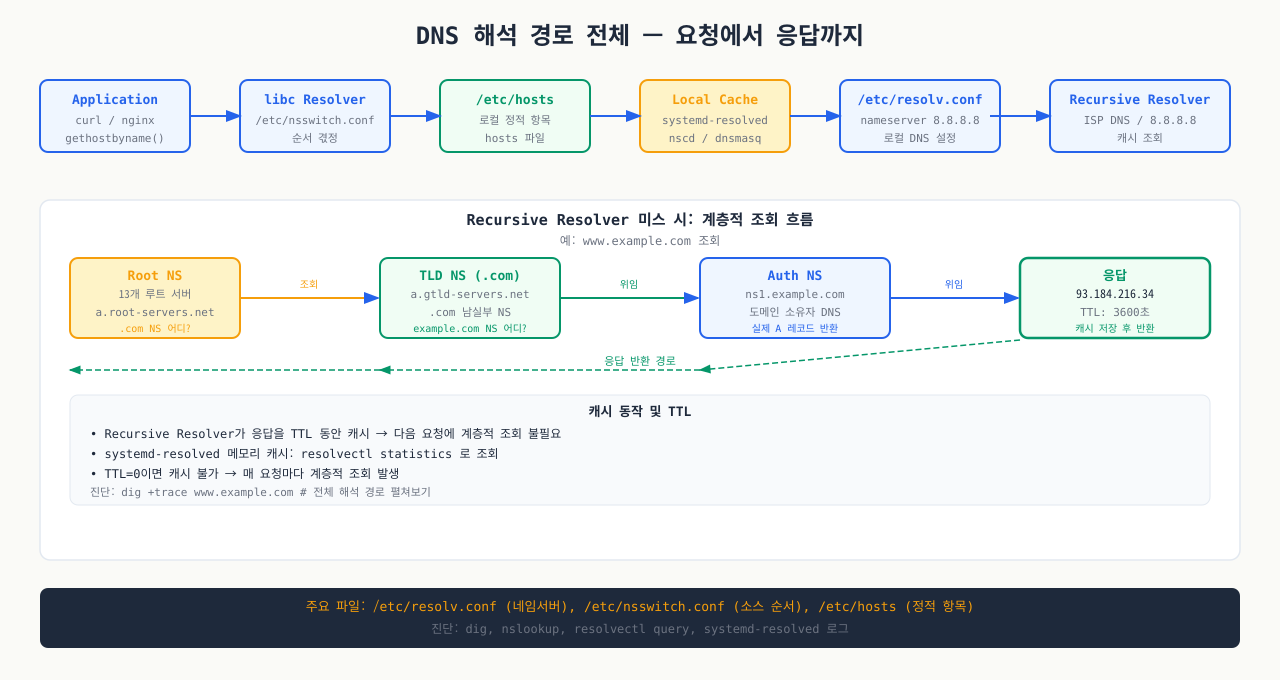
curl https://api.example.com을 실행하면, 커널이 직접 DNS를 조회하는 게 아닙니다. glibc의 Name Service Switch(NSS)가 /etc/nsswitch.conf에 정의된 순서에 따라 여러 소스를 순차적으로 시도합니다. 이 경로를 모르면 "resolv.conf를 고쳤는데 왜 아직 안 되지"라는 상황이 생깁니다.
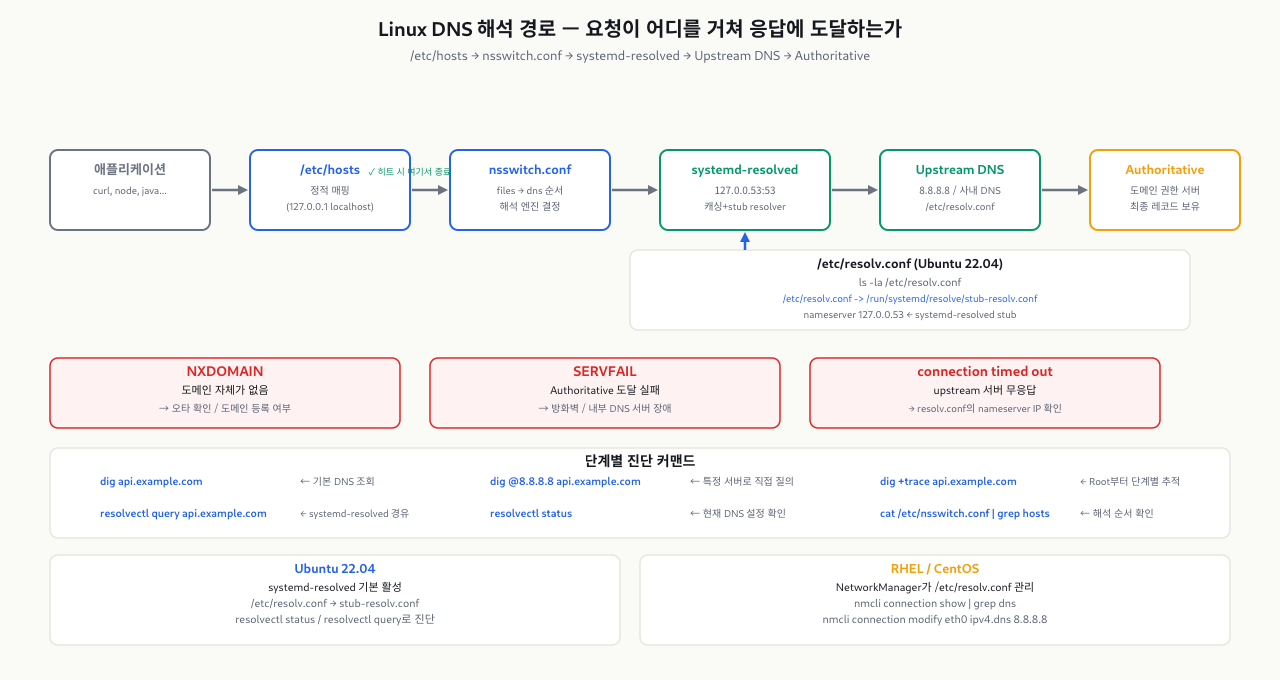
Ubuntu 22.04 기준 해석 경로:
애플리케이션 (curl, wget, your-app) ↓ getaddrinfo() — glibc /etc/nsswitch.conf → "hosts: files mdns4_minimal [NOTFOUND=return] dns" ↓ 1순위: files /etc/hosts → 127.0.0.1 localhost, ::1 localhost ... ↓ 없으면 다음 ↓ 2순위: dns 127.0.0.53:53 → systemd-resolved (stub resolver) ↓ 캐시 없으면 upstream DNS → /run/systemd/resolve/resolv.conf의 nameserver ↓ (보통 DHCP에서 받은 라우터 DNS 또는 회사 내부 DNS) 외부 DNS 서버 → 8.8.8.8, 1.1.1.1 등
nsswitch.conf가 중요한 이유: /etc/hosts가 먼저 확인됩니다. 테스트 목적으로 hosts 파일에 임시 항목을 추가했다가 지우지 않으면, DNS 응답과 다른 IP로 연결이 됩니다.
bash# 현재 hosts 순서 확인 grep "^hosts:" /etc/nsswitch.conf # hosts: files mdns4_minimal [NOTFOUND=return] dns # /etc/hosts 내용 확인 (엉뚱한 항목이 있을 수 있음) cat /etc/hosts
`systemd-resolved`의 역할: Ubuntu 18.04 이후 기본 활성화된 로컬 DNS 캐시 데몬입니다. 127.0.0.53:53에서 리스닝하며 다음 역할을 합니다.
| 역할 | 설명 |
|---|---|
| DNS 캐싱 | TTL 내 반복 질의는 upstream 요청 없이 바로 응답 |
| 검색 도메인 처리 | search corp.example.com 접미사를 자동 추가 |
| per-link DNS | 각 네트워크 인터페이스별로 다른 DNS 서버 사용 가능 |
| DNSSEC 검증 | 옵션으로 활성화 가능 |
실습 1 — Ubuntu vs RHEL DNS 설정 차이 파악
Ubuntu 22.04와 RHEL/CentOS 계열은 DNS 설정 관리 방식이 다릅니다. 같은 명령이 다르게 동작하는 이유를 이해하면 혼란이 사라집니다.
Ubuntu 22.04에서는 systemd-resolved가 DNS를 관리합니다.
bash# 전체 DNS 설정 상태 확인 (가장 먼저 실행) resolvectl status # 특정 인터페이스의 DNS 설정만 확인 resolvectl status eth0
출력 예시:
Global Protocols: -LLMNR -mDNS -DNSOverTLS DNSSEC=no/unsupported resolv.conf mode: stub DNS Servers: 10.0.1.1 DNS Domain: corp.example.com Link 2 (eth0) Current Scopes: DNS Protocols: +DefaultRoute ... Current DNS Server: 10.0.1.1 DNS Servers: 10.0.1.1 8.8.8.8 DNS Domain: corp.example.com
읽는 법:
resolv.conf mode: stub—/etc/resolv.conf가127.0.0.53을 가리키는 정상 상태Current DNS Server— 실제로 질의 중인 upstream DNSDNS Domain— 검색 도메인 (단축 이름api를api.corp.example.com으로 확장)
bash# DNS 캐시 비우기 (설정 변경 후 또는 스테일 캐시 의심 시) sudo resolvectl flush-caches # 특정 도메인 질의 테스트 (systemd-resolved 경유) resolvectl query api.example.com
bashresolvectl status
RHEL 8+, CentOS Stream, Rocky Linux는 NetworkManager가 DNS를 관리합니다. systemd-resolved는 기본 비활성화입니다.
bash# 네트워크 인터페이스별 DNS 설정 확인 nmcli dev show | grep DNS # 현재 연결(connection)의 DNS 설정 확인 nmcli con show $(nmcli -t -f NAME,DEVICE con show --active | head -1 | cut -d: -f1) # DNS 서버 변경 (RHEL/CentOS) sudo nmcli con mod eth0 ipv4.dns "8.8.8.8 1.1.1.1" sudo nmcli con up eth0
Ubuntu vs RHEL 비교:
| 항목 | Ubuntu 22.04 | RHEL 8+ |
|---|---|---|
| DNS 관리 주체 | systemd-resolved |
NetworkManager |
| 로컬 stub | 127.0.0.53:53 |
없음 (직접 resolv.conf) |
| resolv.conf | 심볼릭 링크 | 실제 파일 |
| DNS 캐시 비우기 | resolvectl flush-caches |
systemctl restart NetworkManager |
| DNS 설정 확인 | resolvectl status |
nmcli dev show | grep DNS |
bashnmcli dev show | grep DNS

DNS 문제 진단에서 dig는 가장 신뢰할 수 있는 도구입니다. nslookup보다 출력이 상세하고 옵션도 풍부합니다. 세 가지 패턴만 알면 대부분의 상황을 커버할 수 있습니다.
패턴 1: 공용 DNS로 직접 질의 — systemd-resolved 우회
bash# 로컬 DNS(systemd-resolved)를 완전히 우회하고 구글 DNS에 직접 질의 dig @8.8.8.8 api.example.com # 응답 섹션만 간결하게 (스크립트에서 유용) dig @8.8.8.8 api.example.com +short
이 명령이 성공하고 dig api.example.com이 실패하면 → 로컬 DNS 문제입니다.
패턴 2: 재귀 추적 — Root부터 Authoritative까지 전체 경로
bash# Root NS부터 Authoritative까지 전체 위임 경로 추적 dig +trace api.example.com
출력 예시 (요약):
. 518400 IN NS a.root-servers.net. com. 172800 IN NS a.gtld-servers.net. example.com. 172800 IN NS ns1.example.com. api.example.com. 300 IN A 93.184.216.34
Root → .com TLD → example.com Authoritative 순서로 위임되는 흐름이 보입니다. 특정 단계에서 응답이 없으면 그 구간이 문제입니다.
패턴 3: 특정 레코드 타입 조회
bash# A 레코드 (IPv4 주소) dig api.example.com A # AAAA 레코드 (IPv6 주소) dig api.example.com AAAA # MX 레코드 (메일 서버) dig example.com MX # SOA — 도메인 권한 정보 (NXDOMAIN 의심 시 권한 네임서버 확인) dig example.com SOA # PTR — 역방향 조회 (IP → 도메인) dig -x 93.184.216.34
응답 status 값 해석:
| Status | 의미 | 다음 행동 |
|---|---|---|
NOERROR |
성공 (레코드 없어도 NOERROR 가능) | ANSWER SECTION 확인 |
NXDOMAIN |
도메인이 존재하지 않음 | 오타 확인, Authoritative에 레코드 등록 여부 확인 |
SERVFAIL |
서버 처리 오류 | DNS 서버 상태, 방화벽 UDP 53, DNSSEC 설정 확인 |
REFUSED |
서버가 질의 거부 | 해당 DNS 서버가 재귀 질의를 허용하지 않음 |
실습 2 — /etc/resolv.conf 심볼릭 링크 vs 실제 파일
bash# resolv.conf가 링크인지 실제 파일인지 확인 ls -la /etc/resolv.conf
Ubuntu 22.04 (정상 상태):
lrwxrwxrwx 1 root root 39 Jan 01 00:00 /etc/resolv.conf -> ../run/systemd/resolve/stub-resolv.conf
RHEL 8+ / 링크가 깨진 경우:
-rw-r--r-- 1 root root 73 Jan 01 00:00 /etc/resolv.conf
Ubuntu에서 심볼릭 링크 대상이 두 가지인 이유:
| 링크 대상 | 내용 | 특징 |
|---|---|---|
/run/systemd/resolve/stub-resolv.conf |
nameserver 127.0.0.53 |
기본값. systemd-resolved 캐싱 활용 |
/run/systemd/resolve/resolv.conf |
실제 upstream DNS 목록 | systemd-resolved 우회, 직접 연결 |
bash# stub-resolv.conf 내용 확인 cat /run/systemd/resolve/stub-resolv.conf # nameserver 127.0.0.53 # options edns0 trust-ad # search corp.example.com # 실제 upstream DNS 확인 cat /run/systemd/resolve/resolv.conf # nameserver 10.0.1.1 # nameserver 8.8.8.8
bashls -la /etc/resolv.conf
이미 /etc/resolv.conf가 실제 파일로 교체된 경우, 또는 링크가 잘못된 대상을 가리키는 경우 복원 방법입니다.
bash# 현재 링크 대상 확인 readlink -f /etc/resolv.conf # 링크가 깨진 경우: 올바른 stub으로 재연결 sudo ln -sf /run/systemd/resolve/stub-resolv.conf /etc/resolv.conf # 즉시 적용 확인 cat /etc/resolv.conf # nameserver 127.0.0.53 # systemd-resolved 재시작 (설정 변경 후) sudo systemctl restart systemd-resolved sudo resolvectl flush-caches # DNS 해석이 정상화됐는지 확인 resolvectl query google.com
주의: 직접 /etc/resolv.conf에 nameserver 8.8.8.8을 추가하고 싶을 때가 있습니다. Ubuntu에서는 이 파일이 재부팅이나 네트워크 재연결 시 덮어쓰여집니다. 영구 변경은 systemd-resolved 설정 파일을 통해 합니다.
bash# 영구적으로 upstream DNS 추가 (Ubuntu 22.04) sudo mkdir -p /etc/systemd/resolved.conf.d/ cat <<EOF | sudo tee /etc/systemd/resolved.conf.d/dns.conf [Resolve] DNS=8.8.8.8 1.1.1.1 FallbackDNS=8.8.4.4 EOF sudo systemctl restart systemd-resolved
bashsudo ln -sf /run/systemd/resolve/stub-resolv.conf /etc/resolv.conf
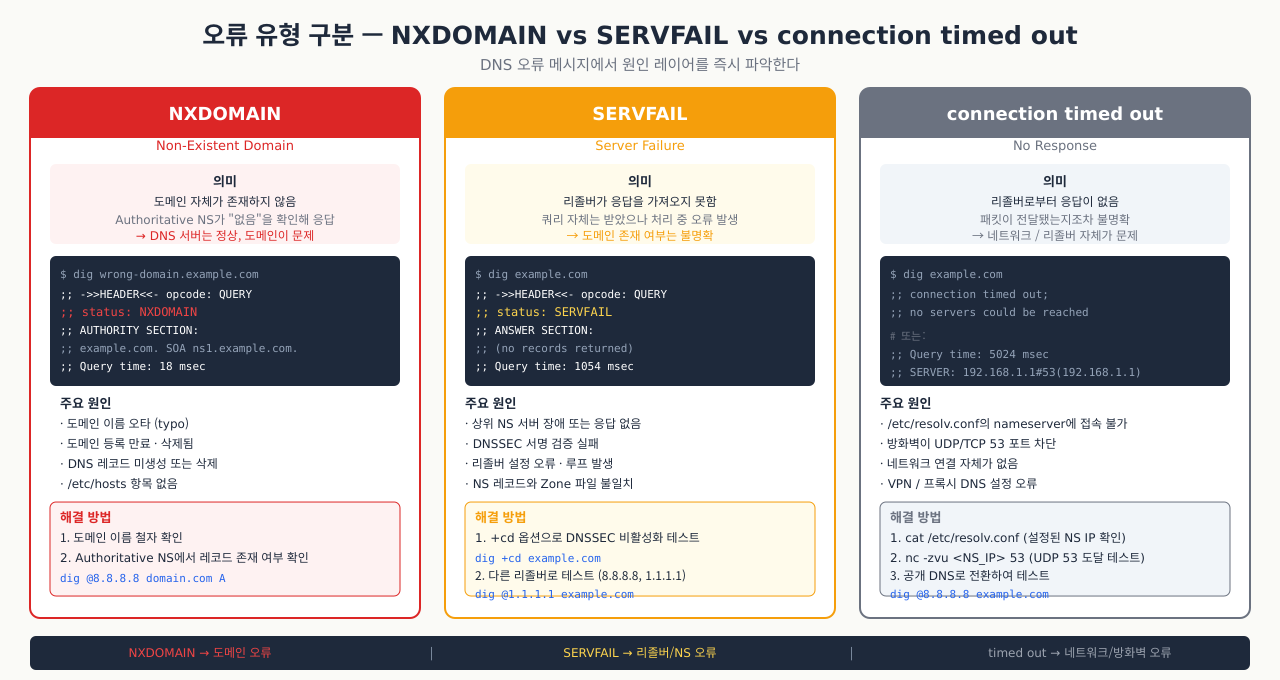
DNS 오류 메시지를 보고 바로 원인 카테고리를 좁히면 진단 시간이 크게 줄어듭니다.
NXDOMAIN — 도메인이 없다
bash$ dig api.internal.corp ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 12345
- Authoritative 서버까지 도달했는데 해당 레코드가 등록되어 있지 않습니다.
- 원인: 오타, 도메인 만료, DNS 레코드 미등록, 검색 도메인(search domain) 문제
- 확인:
dig +trace api.internal.corp로 Authoritative 서버까지 도달하는지 봅니다.
bash# 검색 도메인 문제인지 확인 — 절대 이름으로 조회 dig api.internal.corp. # 끝에 점(.) = 절대 이름, 검색 도메인 미적용
SERVFAIL — 서버가 처리하지 못했다
bash$ dig @10.0.1.53 api.internal.corp ;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 67890
- DNS 리졸버가 응답을 받아왔지만 처리 중 오류가 발생했습니다.
- 원인: 내부 DNS 서버 장애, Authoritative 서버 비응답, DNSSEC 검증 실패, 방화벽이 DNS 응답 패킷을 차단
- 확인: 다른 DNS 서버로 시도 →
dig @8.8.8.8 api.internal.corp
connection timed out — 패킷이 도달하지 못했다
bash$ dig api.example.com ;; connection timed out; no servers could be reached
- DNS 서버로의 UDP 53 패킷 자체가 차단됐거나 DNS 서버가 완전히 다운됐습니다.
- 원인: 방화벽이 UDP 53을 차단,
/etc/resolv.conf의 nameserver IP가 잘못됨, systemd-resolved 다운 - 확인 순서:
bash# 1. systemd-resolved가 살아있는지 확인 systemctl status systemd-resolved # 2. 127.0.0.53 포트가 열려있는지 확인 ss -ulnp | grep 53 # 3. resolv.conf의 nameserver로 ping ping -c 3 $(grep nameserver /etc/resolv.conf | head -1 | awk '{print $2}') # 4. UDP 53 트래픽 직접 확인 sudo tcpdump -i any -n port 53 & dig google.com
오류별 요약:
| 오류 | DNS 서버 도달 | 레코드 존재 | 주요 원인 |
|---|---|---|---|
| NXDOMAIN | O | X | 오타, 미등록, 만료 |
| SERVFAIL | O | 확인 불가 | 내부 DNS 장애, DNSSEC, 방화벽 응답 차단 |
| timed out | X | 확인 불가 | 방화벽 UDP 53 차단, DNS 서버 다운 |
증상: 다음과 같은 오류가 발생합니다.
bash$ curl https://api.internal.corp/health curl: (6) Could not resolve host: api.internal.corp $ dig api.internal.corp ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 28371 ;; ANSWER SECTION: (empty)
1단계: /etc/hosts 확인 — 엉뚱한 항목이 먼저 매칭될 수 있다
bashgrep api.internal.corp /etc/hosts # 출력이 없으면 hosts는 정상
2단계: 검색 도메인 문제인지 확인
bash# 현재 검색 도메인 확인 resolvectl status | grep "DNS Domain" # 절대 이름으로 조회 (끝에 점) dig api.internal.corp. # 공용 DNS로도 같은 결과인지 확인 dig @8.8.8.8 api.internal.corp
3단계: 내부 DNS 서버가 이 도메인을 담당하는지 확인
bash# corp 도메인의 Authoritative 서버 찾기 dig SOA internal.corp # 내부 DNS 서버에 직접 질의 dig @10.0.1.53 api.internal.corp
4단계: systemd-resolved가 내부 도메인을 올바른 DNS 서버로 보내는지 확인
bash# per-link DNS 설정 확인 resolvectl status eth0 # 내부 도메인용 DNS 서버가 설정됐는지 확인 # (VPN 연결 시 corp.example.com 도메인을 내부 DNS로 보내야 함)
해결 — per-domain DNS 라우팅 설정:
bash# 내부 도메인을 내부 DNS 서버로 보내도록 설정 sudo mkdir -p /etc/systemd/resolved.conf.d/ cat <<EOF | sudo tee /etc/systemd/resolved.conf.d/internal.conf [Resolve] DNS=10.0.1.53 Domains=~internal.corp ~corp.example.com EOF sudo systemctl restart systemd-resolved # 적용 확인 resolvectl status | grep -A5 "DNS Domain"
Domains=~internal.corp 에서 ~ 접두사는 "이 도메인은 반드시 이 DNS 서버로"라는 라우팅 규칙입니다.
컨테이너·K8s 환경의 DNS 문제 — CoreDNS와 ndots 설정
컨테이너 환경에서는 DNS 문제가 더 복잡해집니다. 호스트 OS의 DNS 설정이 아니라 컨테이너 런타임과 K8s 내부 DNS(CoreDNS)가 별도로 동작합니다.
Docker 컨테이너 DNS 확인
bash# 컨테이너 내부에서 /etc/resolv.conf 확인 docker exec -it my-container cat /etc/resolv.conf # nameserver 127.0.0.11 ← Docker 내부 DNS # options ndots:0 # 컨테이너 안에서 DNS 질의 테스트 docker exec -it my-container nslookup google.com docker exec -it my-container dig api.internal.corp # 컨테이너의 DNS 서버 직접 지정 (런타임 옵션) docker run --dns 8.8.8.8 --dns 8.8.4.4 my-image
K8s에서 자주 만나는 ndots 문제
K8s Pod의 /etc/resolv.conf에는 기본으로 options ndots:5가 설정됩니다. ndots:5는 도메인에 .(점)이 5개 미만이면 검색 도메인을 먼저 붙여 시도한다는 뜻입니다.
# K8s Pod 내부 /etc/resolv.conf 예시 nameserver 10.96.0.10 ← CoreDNS ClusterIP search default.svc.cluster.local svc.cluster.local cluster.local options ndots:5
api.example.com을 조회하면 점이 2개라서 5개 미만 → 먼저 아래를 순서대로 시도합니다:
api.example.com.default.svc.cluster.localapi.example.com.svc.cluster.localapi.example.com.cluster.local- 실패 후
api.example.com(원래 이름)
외부 도메인 조회마다 불필요한 CoreDNS 질의가 3~4번 추가로 발생합니다. 고트래픽 서비스에서 CoreDNS 부하 원인이 됩니다.
bash# K8s에서 CoreDNS 상태 확인 kubectl -n kube-system get pods -l k8s-app=kube-dns kubectl -n kube-system logs -l k8s-app=kube-dns --tail=50 # Pod DNS 설정 확인 kubectl exec -it my-pod -- cat /etc/resolv.conf # ndots 줄이기 (Pod spec에서) # dnsConfig: # options: # - name: ndots # value: "2" # 외부 도메인을 절대 이름으로 조회 (ndots 우회) # 코드에서 api.example.com. 처럼 끝에 점을 붙이거나 # ndots:1 로 줄이면 불필요한 질의를 줄일 수 있음
CoreDNS가 특정 도메인을 못 찾을 때
bash# CoreDNS 설정(ConfigMap) 확인 kubectl -n kube-system get configmap coredns -o yaml # forward 플러그인: 클러스터 외부 도메인을 어디로 보낼지 확인 # forward . /etc/resolv.conf → 노드의 DNS로 전달 # forward . 8.8.8.8 → 구글 DNS로 전달
컨테이너 DNS 문제는 대부분 세 가지 중 하나입니다: 호스트 DNS 설정 → Docker 데몬 DNS 설정 → K8s CoreDNS 설정. 어느 레이어인지 먼저 특정하고, 그 레이어에서 dig나 nslookup으로 재현하면 빠르게 좁힐 수 있습니다.
다음 모듈에서는 포트와 네트워크 진단 — ss, netstat, lsof, nmap으로 열린 포트를 확인하고 서비스 연결 문제를 추적하는 방법을 다룹니다.
'Linux' 카테고리의 다른 글
| [Linux] SSH 고급 & 보안 하드닝 (0) | 2026.05.22 |
|---|---|
| [Linux] 포트 & 네트워크 진단 (0) | 2026.05.22 |
| [Linux] 네트워킹 기초 (Networking Basics) (0) | 2026.05.22 |
| [Linux] 디스크 트러블슈팅 (0) | 2026.05.22 |
| [Linux] LVM & 볼륨 관리 (0) | 2026.05.22 |