새벽 2시, 슬랙 알림이 울립니다. "No space left on device — 서비스 쓰기 실패." df -h를 치니 루트 파티션이 100%입니다. du -sh /*로 큰 디렉토리를 찾아가다가 /var/log에 30GB짜리 로그가 쌓여 있습니다. 지웠는데 df -h가 여전히 100%. 알고 보니 삭제한 파일을 nginx 프로세스가 계속 열고 있어서 공간이 실제로 반환되지 않은 것이었습니다. lsof | grep deleted를 치고서야 원인을 찾았습니다.
df → du → lsof, 이 세 명령의 순서가 디스크 장애 진단의 기본입니다.
디스크와 스토리지 관리
lsblk -f
df -hT
sudo apt install -y sysstat iotop

서버에 새 디스크를 붙였는데 ls /dev에는 보이는데 파일로 저장할 수가 없고, df -h에도 나타나지 않습니다. 또는 df -h로 보면 공간이 충분한데 파일 쓰기에서 "No space left on device" 에러가 나기도 합니다. 이런 상황에서 원인을 찾으려면 물리 디스크가 파티션, 파일시스템, 마운트 포인트를 거쳐 경로가 되기까지의 계층 구조를 알아야 합니다. 어느 단계가 빠졌는지 파악하면 원인을 빠르게 좁힐 수 있습니다.
리눅스에서 디스크는 추상화 계층을 거쳐 사용자에게 노출됩니다. 물리 하드웨어부터 실제 파일 경로까지 4단계 구조로 이해하면 장애 원인을 빠르게 추적할 수 있습니다.
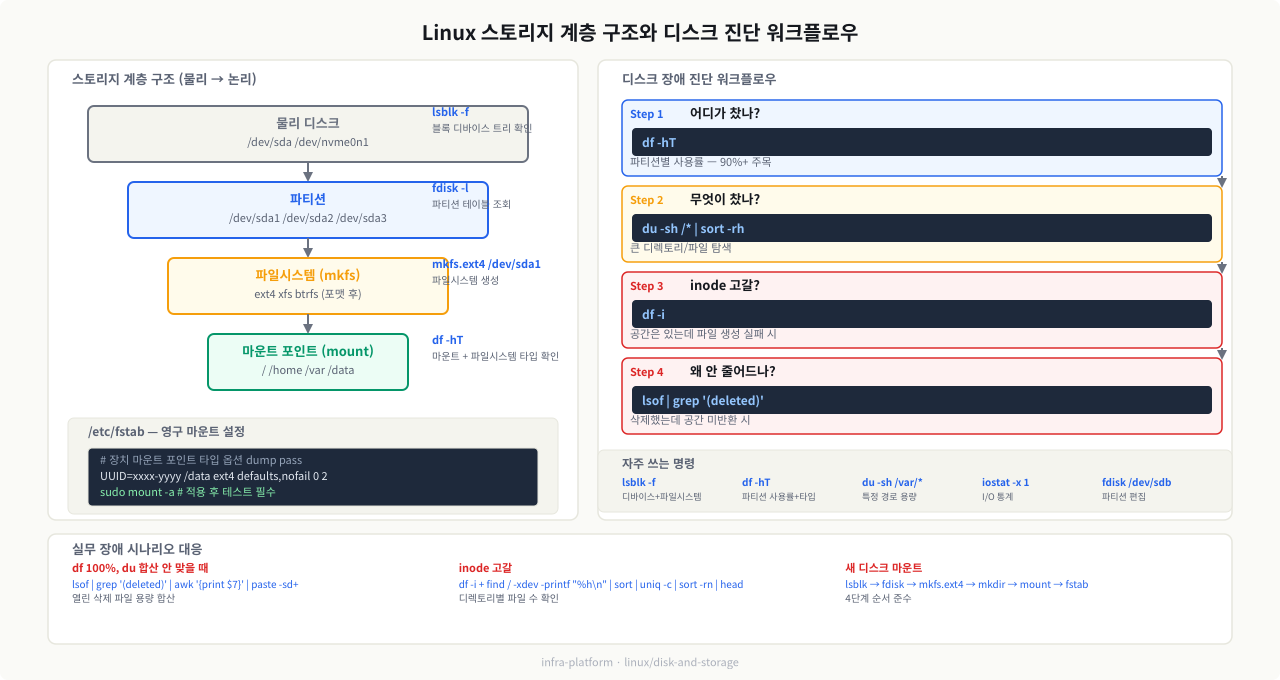
물리 디스크 (Physical Disk) └── 파티션 (Partition) ← 디스크를 논리적으로 분할 └── 파일시스템 (Filesystem) ← 데이터 저장 구조 └── 마운트 포인트 (Mount Point) ← 접근 경로
장치 파일 명명 규칙
리눅스는 모든 하드웨어를 /dev/ 디렉토리 아래 파일로 표현합니다.
| 장치 경로 | 설명 |
|---|---|
/dev/sda |
첫 번째 SATA/SAS 디스크 |
/dev/sdb |
두 번째 SATA/SAS 디스크 |
/dev/sda1 |
/dev/sda의 첫 번째 파티션 |
/dev/sda2 |
/dev/sda의 두 번째 파티션 |
/dev/nvme0n1 |
첫 번째 NVMe SSD |
/dev/nvme0n1p1 |
/dev/nvme0n1의 첫 번째 파티션 |
/dev/vda |
가상 머신(KVM/QEMU)의 첫 번째 가상 디스크 |
명명 패턴 읽는 법:
nvme0n1p2에서0은 컨트롤러 번호,n1은 네임스페이스(디스크) 번호,p2는 파티션 번호입니다.
파티션 테이블: MBR vs GPT
디스크를 파티션으로 나누려면 파티션 테이블 형식을 먼저 선택해야 합니다.
| 항목 | MBR (Master Boot Record) | GPT (GUID Partition Table) |
|---|---|---|
| 최대 디스크 크기 | 2TB | 9.4ZB (사실상 무제한) |
| 최대 파티션 수 | 4개 (주 파티션) | 128개 |
| 부트 지원 | BIOS | UEFI (BIOS도 가능) |
| 데이터 이중화 | 없음 | 헤더와 파티션 테이블 이중 저장 |
| 현재 권장 여부 | 레거시 시스템 | 신규 시스템 표준 |
2TB 이상 디스크나 신규 서버에는 반드시 GPT를 사용하세요. 클라우드 환경(AWS, GCP, Azure)의 부팅 볼륨은 대부분 GPT로 포맷되어 있습니다.
— — —
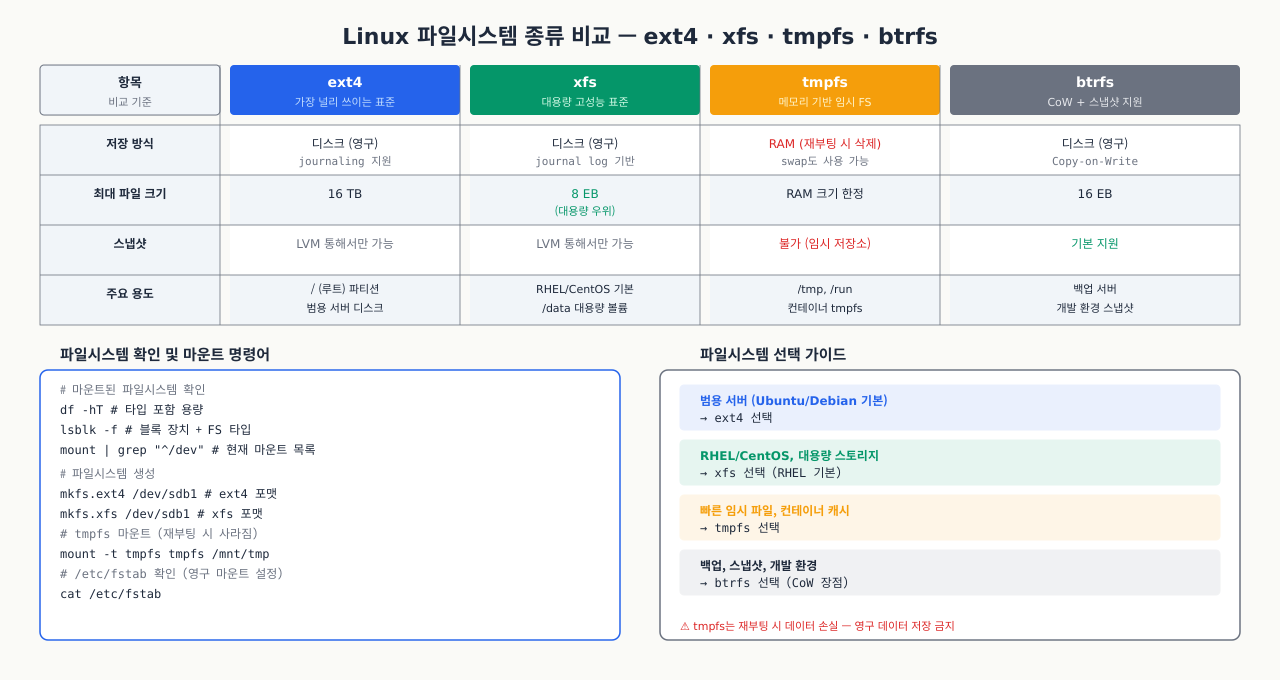
새 디스크를 추가하거나 파티션을 포맷할 때 mkfs.ext4를 쓸지 mkfs.xfs를 쓸지 선택해야 합니다. 대부분의 경우 Ubuntu는 ext4를, RHEL/CentOS는 XFS를 기본으로 씁니다. 파일시스템 종류가 다르면 복구 방법도, 대용량 파일 처리 특성도 달라지기 때문에 나중에 바꾸려면 데이터를 옮기고 포맷을 다시 해야 합니다. 처음 선택이 중요하고, 어떤 상황에 어떤 파일시스템이 맞는지를 알아야 합니다.
파티션 위에 올라가는 파일시스템은 데이터를 어떻게 저장하고 복구할지를 결정합니다. 리눅스 환경에서 주로 만나게 될 세 가지 파일시스템을 비교합니다.
| 항목 | ext4 | XFS | Btrfs |
|---|---|---|---|
| 안정성 | 매우 높음 (오랜 검증) | 높음 | 중간 (계속 개선 중) |
| 최대 파일 크기 | 16TB | 8EB | 16EB |
| 최대 파일시스템 크기 | 1EB | 8EB | 16EB |
| 저널링 | 지원 | 지원 (메타데이터) | 지원 (Copy-on-Write) |
| 스냅샷 | 미지원 | 미지원 (LVM 필요) | 네이티브 지원 |
| 온라인 축소 | 불가 | 불가 | 가능 |
| 주요 사용 사례 | 범용, 부팅 볼륨 | 대용량 파일, 데이터베이스 | 백업 서버, NAS |
| 대표 배포판 | Ubuntu, Debian | RHEL, Rocky Linux | openSUSE |
실무 선택 기준
- 일반 서버 루트 볼륨: ext4 (안정성 우선, 검증된 복구 도구)
- 데이터베이스 서버: XFS (대용량 순차 I/O 성능 우수)
- 백업/스냅샷 서버: Btrfs (스냅샷 기능 활용)
- 클라우드 AWS EC2: 기본값은 ext4, Amazon Linux 2023은 XFS
inode란? 파일시스템은 각 파일에 대한 메타데이터(크기, 권한, 타임스탬프, 위치 등)를 inode에 저장합니다. inode 수는 파일시스템 생성 시 고정되며, inode를 모두 소진하면 디스크 공간이 남아 있어도 파일을 생성할 수 없습니다.
— — —
실습: 디스크 상태 진단부터 I/O 분석까지
실습 전 디렉토리와 예제 파일을 먼저 준비합니다.
bash# 실습 디렉토리 준비 mkdir -p /tmp/linux/part3/exam_1 && cd /tmp/linux/part3/exam_1 # 디스크 실습용 테스트 파일 생성 dd if=/dev/urandom of=/tmp/linux/part3/exam_1/testfile_100m.bin bs=1M count=100 2>/dev/null echo "테스트 파일 생성 완료: $(du -sh /tmp/linux/part3/exam_1/testfile_100m.bin)"
이제 실습을 진행합니다.
df(disk free)는 현재 마운트된 모든 파일시스템의 용량 정보를 보여줍니다. -h는 사람이 읽기 좋은 단위(GB, MB), -T는 파일시스템 타입을 추가로 출력합니다.
bashdf -hT
Filesystem Type Size Used Avail Use% Mounted on /dev/nvme0n1p1 ext4 30G 14G 15G 49% / tmpfs tmpfs 3.9G 0 3.9G 0% /dev/shm /dev/nvme0n1p3 ext4 100G 67G 28G 71% /var /dev/sdb1 xfs 500G 312G 188G 63% /data /dev/sdc1 xfs 2.0T 1.1T 900G 56% /backup tmpfs tmpfs 3.9G 1.2M 3.9G 1% /run
각 컬럼 읽는 법:
Filesystem: 장치 파일 경로Type: 파일시스템 종류Size: 전체 용량Used: 사용 중인 용량Avail: 실제 사용 가능한 용량 (루트 예약 공간 제외)Use%: 사용률 — 85% 이상이면 즉시 확인 필요Mounted on: 마운트 포인트
bash# 특정 디렉토리가 어떤 파티션에 속하는지 확인 df -hT /var/log # tmpfs(메모리 기반 임시 파일시스템) 제외 df -hT --exclude-type=tmpfs # 사용률 내림차순 정렬 (경보 대응 시 유용) df -h | sort -rk5 | head -10
bashdf -hT
— — —
du(disk usage)는 파일과 디렉토리의 실제 점유 용량을 계산합니다. df로 어떤 파티션이 가득 찼는지 파악했다면, du로 주범을 찾습니다.
bashdu -sh /var/log/* | sort -rh | head -20
4.2G /var/log/journal 1.8G /var/log/nginx 956M /var/log/postgresql 312M /var/log/syslog 189M /var/log/auth.log 87M /var/log/kern.log 45M /var/log/apt 12M /var/log/dpkg.log 8.4M /var/log/faillog 2.1M /var/log/btmp
옵션 설명:
-s: 각 항목의 합계만 출력 (하위 디렉토리 개별 표시 안 함)-h: 사람이 읽기 좋은 단위sort -rh: 용량 기준 내림차순 정렬 (-h는 K/M/G 단위 인식)head -20: 상위 20개만 출력
bash# 현재 디렉토리 기준으로 하위 1단계만 분석 du -sh /* 2>/dev/null | sort -rh | head -15 # 특정 크기 이상 파일 찾기 (100MB 이상) find /var -type f -size +100M -exec ls -lh {} \; 2>/dev/null # 최근 24시간 내 수정된 대용량 파일 추적 find / -type f -size +50M -mtime -1 2>/dev/null | xargs ls -lh
주의:
du -sh /*는 전체 파일시스템을 탐색하므로 대형 서버에서는 시간이 걸릴 수 있습니다. I/O 부하가 높은 운영 서버에서는ionice -c3 du -sh /var/*처럼 I/O 우선순위를 낮춰서 실행하세요.
bashdu -sh /var/log/* | sort -rh | head -20
— — —
lsblk는 시스템의 모든 블록 디바이스(디스크, 파티션, LVM 볼륨 등)를 트리 형태로 보여줍니다. -f 옵션을 추가하면 파일시스템 타입과 UUID, 마운트 포인트까지 함께 출력됩니다.
bashlsblk -f
NAME FSTYPE FSVER LABEL UUID FSAVAIL FSUSE% MOUNTPOINTS nvme0n1 ├─nvme0n1p1 vfat FAT32 4E21-3A9F 511M 1% /boot/efi ├─nvme0n1p2 ext4 1.0 a3f2c1d8-7b4e-4f91-9c2a-1e8f6b3d5a7c 884M 11% /boot └─nvme0n1p3 ext4 1.0 b7d4e2f9-3c1a-4b82-8d5f-9e7a2c4b6f1e 15G 47% / sdb └─sdb1 xfs data f1a2b3c4-d5e6-7f8a-9b0c-1d2e3f4a5b6c 188G 63% /data sdc └─sdc1 xfs backup 9a8b7c6d-5e4f-3a2b-1c0d-9e8f7a6b5c4d 900G 55% /backup
트리 구조 읽는 법:
- 최상위 항목(
nvme0n1,sdb)이 물리 디스크 ├─,└─하위 항목이 파티션UUID는 장치 이름 대신/etc/fstab에서 안정적인 식별자로 사용
bash# 디스크 크기 정보도 함께 출력 lsblk -f -o NAME,FSTYPE,SIZE,FSAVAIL,FSUSE%,MOUNTPOINTS # 특정 디바이스만 확인 lsblk -f /dev/sdb # 파티션 테이블 상세 정보 (루트 권한 필요) sudo fdisk -l /dev/nvme0n1
fdisk -l 출력 예시:
Disk /dev/nvme0n1: 30 GiB, 32212254720 bytes, 62914560 sectors Disk model: Amazon Elastic Block Store Units: sectors of 1 * 512 = 512 bytes Distor size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: gpt Device Start End Sectors Size Type /dev/nvme0n1p1 2048 1050623 1048576 512M EFI System /dev/nvme0n1p2 1050624 3147775 2097152 1G Linux filesystem /dev/nvme0n1p3 3147776 62914526 59766751 28.5G Linux filesystem
bashlsblk -f
— — —
마운트는 파일시스템을 디렉토리 트리에 연결하는 작업입니다. 수동 마운트는 재부팅 시 사라지므로, 영구 설정은 /etc/fstab에 등록해야 합니다.
bash# 현재 마운트된 파일시스템 목록 확인 mount | grep -v "^cgroup\|^proc\|^sys\|^tmpfs\|^devtmpfs"
/dev/nvme0n1p3 on / type ext4 (rw,relatime) /dev/nvme0n1p2 on /boot type ext4 (rw,relatime) /dev/nvme0n1p1 on /boot/efi type vfat (rw,relatime,fmask=0077) /dev/sdb1 on /data type xfs (rw,relatime,attr2,inode64,logbufs=8,noquota) /dev/sdc1 on /backup type xfs (rw,relatime,attr2,inode64,logbufs=8,noquota)
수동 마운트 및 언마운트:
bash# 마운트 포인트 디렉토리 생성 sudo mkdir -p /mnt/external # 파일시스템 마운트 sudo mount /dev/sdd1 /mnt/external # 읽기 전용으로 마운트 sudo mount -o ro /dev/sdd1 /mnt/external # 언마운트 (사용 중인 프로세스가 있으면 실패) sudo umount /mnt/external # 사용 중인 프로세스 확인 후 언마운트 lsof +D /mnt/external sudo fuser -m /mnt/external
`/etc/fstab` 영구 마운트 설정:
bash# fstab 형식: <장치> <마운트포인트> <타입> <옵션> <dump> <fsck> cat /etc/fstab
# /etc/fstab UUID=b7d4e2f9-3c1a-4b82-8d5f-9e7a2c4b6f1e / ext4 defaults 0 1 UUID=a3f2c1d8-7b4e-4f91-9c2a-1e8f6b3d5a7c /boot ext4 defaults 0 2 UUID=4E21-3A9F /boot/efi vfat umask=0077 0 1 UUID=f1a2b3c4-d5e6-7f8a-9b0c-1d2e3f4a5b6c /data xfs defaults,nofail 0 2 UUID=9a8b7c6d-5e4f-3a2b-1c0d-9e8f7a6b5c4d /backup xfs defaults,nofail 0 2
fstab 주요 옵션:
| 옵션 | 설명 |
|---|---|
defaults |
rw, suid, dev, exec, auto, nouser, async 기본값 묶음 |
nofail |
마운트 실패해도 부팅 계속 진행 (외부 볼륨 필수) |
noatime |
파일 접근 시 atime 갱신 안 함 (I/O 성능 향상) |
ro |
읽기 전용 마운트 |
0 0 |
dump 비활성화, fsck 건너뜀 |
0 1 |
루트 파일시스템용 fsck 우선순위 |
0 2 |
루트 이후 fsck 실행 |
bash# fstab 수정 후 문법 검증 없이 전체 마운트 시도 (재부팅 전 테스트) sudo mount -a # UUID 확인 방법 blkid /dev/sdb1
bashmount / umount + /etc/fstab
— — —
CPU와 메모리가 여유 있는데 서버가 느리다면 디스크 I/O 병목일 수 있습니다. iostat과 iotop으로 I/O 현황을 실시간으로 파악합니다.
bash# 1초 간격으로 확장 I/O 통계 출력 (sysstat 패키지 필요) iostat -x 1
Linux 5.15.0-89-generic 03/26/2026 _x86_64_ (4 CPU) avg-cpu: %user %nice %system %iowait %steal %idle 8.25 0.00 3.42 31.67 0.12 56.54 Device r/s w/s rkB/s wkB/s r_await w_await util nvme0n1 12.40 245.80 156.80 15732.40 0.42 2.18 67.3% sdb 0.20 189.60 2.60 12134.40 1.20 35.47 98.2% sdc 0.10 4.20 1.20 268.80 2.10 8.34 3.1%
핵심 지표 읽는 법:
%iowait: CPU가 I/O 대기로 낭비한 비율 — 20% 이상이면 I/O 병목 의심r/s,w/s: 초당 읽기/쓰기 요청 수rkB/s,wkB/s: 초당 읽기/쓰기 처리량 (KB)r_await,w_await: 읽기/쓰기 평균 응답시간 (ms) — HDD 20ms, SSD 1ms 이상이면 과부하util: 장치 사용률 — `sdb`가 98.2%로 포화 상태
bash# 프로세스별 I/O 사용량 실시간 모니터링 (루트 권한 필요) sudo iotop -o -d 2 # -o: I/O를 실제로 사용 중인 프로세스만 표시 # -d 2: 2초 간격 갱신
Total DISK READ: 1.23 M/s | Total DISK WRITE: 14.87 M/s TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND 8421 be/4 postgres 0.00 B/s 13.45 M/s 0.00% 89.23% postgres: checkpointer 3201 be/4 www-data 892.34 K/s 1.23 M/s 0.00% 8.12% nginx: worker 891 be/4 root 0.00 B/s 198.23 K/s 0.00% 1.34% journald
bash# iotop 없을 때 대안: /proc/diskstats로 수동 확인 cat /proc/diskstats | awk '{print $3, $6, $10}' | grep -v "^loop\|^ram" # 특정 장치의 I/O 대기 큐 크기 확인 cat /sys/block/sdb/queue/nr_requests
bashiostat -x 1 / iotop
— — —
새 서버나 스토리지 볼륨을 받았을 때, 또는 성능 이슈가 의심될 때 디스크 순차 쓰기 속도를 측정합니다.
bash# /tmp에 1GB 파일 쓰기 테스트 (bs=1M × count=1000) dd if=/dev/zero of=/tmp/testfile bs=1M count=1000 conv=fdatasync
1000+0 records in 1000+0 records out 1048576000 bytes (1.0 GB, 1000 MiB) copied, 3.47218 s, 302 MB/s
옵션 설명:
if=/dev/zero: 입력 소스로/dev/zero(무한 0 바이트 스트림) 사용of=/tmp/testfile: 출력 파일 경로bs=1M: 블록 크기 1MB (큰 블록 = 순차 I/O 시나리오)count=1000: 1000블록 = 1GBconv=fdatasync: 커널 버퍼 캐시를 거치지 않고 디스크에 직접 쓰기 (실제 디스크 속도 측정)
속도 기준값 (참고):
| 스토리지 유형 | 예상 순차 쓰기 속도 |
|---|---|
| AWS EBS gp3 | 125 ~ 1000 MB/s |
| AWS EBS io2 | 256 KB/s ~ 4 GB/s |
| NVMe SSD (로컬) | 1 ~ 7 GB/s |
| SATA SSD | 300 ~ 560 MB/s |
| HDD (SATA) | 80 ~ 200 MB/s |
bash# 테스트 후 반드시 파일 삭제 rm /tmp/testfile # 읽기 속도 테스트 (페이지 캐시 비우기 후 측정) sudo sh -c 'echo 3 > /proc/sys/vm/drop_caches' dd if=/tmp/testfile of=/dev/null bs=1M
주의: 운영 서버에서
dd테스트 시 대상 경로를 반드시 확인하세요.of=/dev/sdb처럼 장치 파일을 직접 지정하면 해당 디스크 데이터가 영구 삭제됩니다.
bashdd if=/dev/zero of=/tmp/test bs=1M count=1000
— — —
트러블슈팅: 현장에서 마주치는 디스크 장애
증상
[Errno 28] No space left on device: '/var/log/app.log' write error: No space left on device cp: cannot create regular file '/tmp/backup.tar.gz': No space left on device
원인 진단
1단계: 어떤 파티션이 가득 찼는지 파악
bashdf -h
Filesystem Size Used Avail Use% Mounted on /dev/nvme0n1p3 30G 30G 0 100% /var
2단계: 문제 파티션에서 주범 추적
bashdu -sh /var/* 2>/dev/null | sort -rh | head -15
18G /var/log 7.2G /var/cache 3.1G /var/lib
bashdu -sh /var/log/* 2>/dev/null | sort -rh | head -10
16G /var/log/journal 1.1G /var/log/nginx 450M /var/log/app
3단계: 즉각 대응
bash# systemd journal 로그 정리 (최근 7일치만 보존) sudo journalctl --vacuum-time=7d # 오래된 로그 아카이브 삭제 sudo find /var/log -name "*.gz" -mtime +30 -delete sudo find /var/log -name "*.log.*" -mtime +14 -delete # /tmp 정리 sudo find /tmp -type f -mtime +3 -delete # 코어 덤프 정리 sudo find /var/crash /tmp -name "core.*" -delete sudo coredumpctl list sudo rm -rf /var/lib/systemd/coredump/*
4단계: 삭제했는데도 공간이 안 늘어날 때 — 열려있는 삭제 파일
파일을 rm으로 삭제해도, 프로세스가 해당 파일을 열고 있으면 실제 블록은 해제되지 않습니다.
bash# 삭제됐지만 프로세스가 여전히 열고 있는 파일 찾기 sudo lsof | grep "(deleted)"
nginx 3201 www-data 3w REG 259,3 9663676416 1234567 /var/log/nginx/access.log (deleted)
bash# 해결: 해당 프로세스 재시작 sudo systemctl restart nginx # 또는 프로세스를 종료하지 않고 파일 내용만 비우기 (PID와 fd 번호 활용) > /proc/3201/fd/3
재발 방지
bash# logrotate 설정 확인 cat /etc/logrotate.d/nginx # systemd journal 최대 크기 제한 sudo sed -i 's/#SystemMaxUse=/SystemMaxUse=2G/' /etc/systemd/journald.conf sudo systemctl restart systemd-journald
— — —
증상
bashtouch /var/www/newfile.txt touch: cannot touch '/var/www/newfile.txt': No space left on device df -h # 여전히 공간 있음 Filesystem Size Used Avail Use% Mounted on /dev/sdb1 500G 245G 255G 49% /var/www # 49%인데 파일 생성 실패?
원인 파악
bashdf -i
Filesystem Inodes IUsed IFree IUse% Mounted on /dev/nvme0n1p3 1966080 1966080 0 100% /var /dev/sdb1 31252480 3421012 27831468 11% /data
/var 파티션의 inode가 100% 소진되었습니다. 디스크 바이트는 남아 있지만 파일을 더 만들 수 없습니다.
주범 찾기
inode를 대량 소비하는 주원인은 작은 파일이 수없이 많은 경우입니다 (이메일 스풀, 캐시, 세션 파일, PHP 세션 등).
bash# 하위 디렉토리별 파일 수 카운트 for dir in /var/*/; do count=$(find "$dir" -type f 2>/dev/null | wc -l) echo "$count $dir" done | sort -rn | head -15
4821903 /var/spool/postfix/deferred/ 342891 /var/cache/php/sessions/ 89234 /var/tmp/
해결
bash# postfix 큐 긴급 정리 (운영 환경 주의) sudo postsuper -d ALL deferred # PHP 세션 파일 정리 (30분 이상 된 것) sudo find /var/cache/php/sessions/ -type f -mmin +30 -delete # 처리 후 inode 확인 df -i /var
재발 방지
bash# 파일시스템 생성 시 inode 밀도 조정 (ext4) # bytes-per-inode 값을 낮추면 inode 수 증가 (파일시스템 생성 시에만 가능) mkfs.ext4 -i 4096 /dev/sdd1 # 기본 16384 대신 4096바이트당 inode 1개
— — —
증상
/etc/fstab을 수정하고 재부팅했더니 서버가 응급 복구 모드로 진입합니다.
[ *** ] A start job is running for /data (2min 30s / no limit) [FAILED] Failed to mount /data. You are in emergency mode. After logging in, type "journalctl -xb" to view system logs, "systemctl reboot" to reboot, "systemctl default" or "exit" to boot into default mode. Give root password for maintenance (or press Control-D to continue):
원인 유형
- 존재하지 않는 UUID 입력
- 마운트 포인트 디렉토리 미생성
- 잘못된 파일시스템 타입 지정
nofail옵션 누락으로 선택적 볼륨 실패가 부팅 중단 유발
복구 절차
bash# 1. emergency mode에서 root 암호 입력 후 로그인 # 2. 루트 파일시스템을 읽기-쓰기로 재마운트 mount -o remount,rw / # 3. fstab 편집 nano /etc/fstab # 문제가 된 라인 주석 처리 또는 수정 # 4. 구문 검증 mount -a --fake # 실제 마운트 없이 fstab 구문 검사 # 5. 재부팅 reboot
올바른 fstab 작성 패턴
bash# 클라우드/외부 볼륨에는 반드시 nofail 추가 UUID=f1a2b3c4-d5e6-7f8a-9b0c-1d2e3f4a5b6c /data xfs defaults,nofail 0 2 # fstab 수정 후 재부팅 전 반드시 테스트 sudo mount -a # 오류 없으면 안전
예방 습관: fstab 수정 후
sudo mount -a로 반드시 테스트합니다. 클라우드 환경에서 데이터 볼륨에는 반드시nofail을 추가하세요. AWS EC2에서 EBS가 연결되기 전에 인스턴스가 부팅을 시도할 수 있습니다.
— — —
실무 시나리오
새벽 2시, 모니터링 시스템이 운영 서버 /var 파티션 90% 사용률 알람을 발송했습니다. 서비스는 아직 정상이지만 계속 증가하면 수 시간 내에 장애가 발생합니다.
표준 진단 플로우
bash# Step 1: 전체 파티션 상태 파악 df -hT # → /var 파티션이 90% # Step 2: /var 내 주요 디렉토리 용량 분석 sudo du -sh /var/* 2>/dev/null | sort -rh | head -10 # → /var/log 가 가장 크다고 가정 # Step 3: 로그 디렉토리 드릴다운 sudo du -sh /var/log/* 2>/dev/null | sort -rh | head -10 # → /var/log/app/access.log 가 30GB로 비정상 크기 # Step 4: 삭제됐는데 공간이 안 줄어드는지 확인 sudo lsof | grep "(deleted)" | awk '{print $1, $2, $7, $NF}' | sort -k3 -rn | head -10 # → 앱 프로세스가 삭제된 파일을 여전히 열고 있는지 확인 # Step 5: 실시간 쓰기 중인 프로세스 특정 sudo iotop -o -d 1 # Step 6: 로그 로테이션 강제 실행 sudo logrotate -f /etc/logrotate.d/myapp # Step 7: 서비스 재시작으로 파일 핸들 해제 sudo systemctl restart myapp # Step 8: 공간 회복 확인 df -h /var
임시 방편이 아닌 근본 해결
bash# 로그 레벨 확인 (DEBUG 레벨이면 INFO로 낮추기) grep -i "log.level\|LOG_LEVEL" /etc/myapp/config.yaml # logrotate 주기와 보존 정책 검토 cat /etc/logrotate.d/myapp # rotate 7 → 더 짧게, daily → 더 자주 # 로그 볼륨을 별도 파티션으로 분리 검토 (장기 대책)
— — —
새로운 EC2 인스턴스를 시작할 때 /data 볼륨(EBS)이 서비스 시작 전에 반드시 마운트되어 있어야 합니다. 잘못된 순서로 서비스가 먼저 시작되면 /data에 쓰려던 파일이 루트 파티션에 쌓이고, EBS가 나중에 마운트되면 해당 마운트 포인트가 가려집니다.
문제 상황
bash# 서비스 시작 후 EBS가 마운트된 경우 발생하는 문제 ls /data/ # EBS 마운트 전 루트에 쌓인 파일들이 보임 umount /data # EBS 언마운트 ls /data/ # 루트에 쌓인 쓰레기 파일 노출
systemd 의존성으로 마운트 보장
bash# /etc/systemd/system/data.mount 생성 (파일명이 마운트 경로와 일치해야 함) sudo tee /etc/systemd/system/data.mount << 'EOF' [Unit] Description=Data Volume Mount After=local-fs.target [Mount] What=/dev/disk/by-uuid/f1a2b3c4-d5e6-7f8a-9b0c-1d2e3f4a5b6c Where=/data Type=xfs Options=defaults,nofail [Install] WantedBy=multi-user.target EOF # 서비스에서 마운트 의존성 선언 sudo tee /etc/systemd/system/myapp.service << 'EOF' [Unit] Description=My Application After=network.target data.mount Requires=data.mount [Service] ExecStart=/usr/bin/myapp Restart=on-failure [Install] WantedBy=multi-user.target EOF sudo systemctl daemon-reload sudo systemctl enable data.mount myapp
스크립트 방식 마운트 검증 (부트스트랩)
EC2 User Data나 Ansible로 프로비저닝할 때 사용할 수 있는 패턴입니다.
bash#!/bin/bash # /usr/local/bin/ensure-data-mount.sh MOUNT_POINT="/data" DEVICE_UUID="f1a2b3c4-d5e6-7f8a-9b0c-1d2e3f4a5b6c" MAX_WAIT=60 WAITED=0 echo "Waiting for data volume to be available..." while ! blkid | grep -q "$DEVICE_UUID"; do if [ $WAITED -ge $MAX_WAIT ]; then echo "ERROR: Data volume not found after ${MAX_WAIT}s. Aborting." exit 1 fi sleep 2 WAITED=$((WAITED + 2)) echo " Still waiting... (${WAITED}s)" done echo "Device found. Mounting to ${MOUNT_POINT}..." mkdir -p "$MOUNT_POINT" mount UUID="$DEVICE_UUID" "$MOUNT_POINT" if mountpoint -q "$MOUNT_POINT"; then echo "Mount successful: $(df -h $MOUNT_POINT | tail -1)" else echo "ERROR: Mount failed." exit 1 fi
bashchmod +x /usr/local/bin/ensure-data-mount.sh # ExecStartPre에 등록하여 서비스 시작 전 실행 보장
다음 모듈에서는 LVM(Logical Volume Manager) — 파티션 크기를 유연하게 조정하는 논리 볼륨 관리를 다룹니다.
'Linux' 카테고리의 다른 글
| [Linux] 디스크 트러블슈팅 (0) | 2026.05.22 |
|---|---|
| [Linux] LVM & 볼륨 관리 (0) | 2026.05.22 |
| [Linux] Bash 스크립팅 기초 (0) | 2026.05.22 |
| [Linux] 텍스트 처리 (grep/awk/sed) (0) | 2026.05.22 |
| [Linux ] systemd 서비스 관리 (0) | 2026.05.22 |