서버에 올린 앱이 재부팅 후 자동으로 다시 뜨지 않아서 매번 수동으로 켜야 했습니다. nohup으로 실행한 프로세스는 서버가 재시작되면 사라지고, 크래시가 나도 아무도 모릅니다. 이런 상황에서 새벽에 서버가 재부팅됐다면? 아침에 출근해서야 서비스가 죽어있음을 발견하게 됩니다.
systemd 서비스로 등록하면 부팅 시 자동 시작, 크래시 시 자동 재시작, 로그 통합 관리가 모두 해결됩니다. 운영 서버에 앱을 배포할 때 반드시 거치는 과정입니다.
systemd 서비스 관리
1. Unit 파일 구조와 서비스 타입
systemctl --version
systemctl --failed
journalctl --disk-usage
ls /etc/systemd/system/
앱을 systemd 서비스로 등록하려면 어디에 무엇을 써야 하는지 알아야 합니다. 설정 파일 하나의 위치와 내용이 "부팅 시 자동 시작되는 서비스"와 "수동으로 켜야 하는 프로세스"의 차이를 만듭니다. Unit 파일은 크게 세 섹션([Unit], [Service], [Install])으로 구성되고, 각 섹션이 서비스의 다른 측면을 정의합니다. 이 구조를 한 번 이해하면 nginx, postgresql 같은 패키지가 설치한 unit 파일을 읽고 의도를 파악할 수 있고, 직접 서비스를 작성할 때도 막히지 않습니다.
서비스는 Unit 파일로 정의됩니다. 위치: /etc/systemd/system/ (운영자 정의) 또는 /lib/systemd/system/ (패키지 기본값)
![systemd Unit 파일 구조와 서비스 생명주기 — [Unit]/[Service]/[Install] 섹션, systemctl 명령](https://infra-platform.vercel.app/images/linux/systemd-services/unit-file-lifecycle.png)
ini[Unit] Description=My App Service After=network.target postgresql.service Requires=postgresql.service [Service] Type=simple User=myapp WorkingDirectory=/opt/myapp ExecStart=/opt/myapp/bin/server --port 8080 ExecReload=/bin/kill -HUP $MAINPID Restart=always RestartSec=5 Environment=NODE_ENV=production EnvironmentFile=/etc/myapp/env [Install] WantedBy=multi-user.target
핵심 디렉티브:
After: 이 서비스가 시작되기 전에 시작되어야 할 유닛 (순서만, 의존성 아님)Requires: 강한 의존성 — 해당 유닛이 실패하면 이 서비스도 중단Wants: 약한 의존성 — 해당 유닛이 실패해도 이 서비스는 계속 시작Restart=always: 어떤 이유로든 종료 시 자동 재시작EnvironmentFile: 환경 변수를 파일에서 로드 (시크릿 관리에 유용)
서비스 타입 선택 기준:
Type=은 systemd가 서비스의 "준비 완료" 신호를 어떻게 판단하는지를 지정합니다. 대부분의 현대 앱은 simple이 맞고, 포크 방식 데몬이나 D-Bus 서비스는 별도 타입이 필요합니다.
| Type | 동작 | 사용 예 |
|---|---|---|
simple |
ExecStart가 메인 프로세스 | 대부분의 현대 앱 |
forking |
ExecStart가 fork 후 종료 | 전통적인 데몬 |
notify |
준비 완료를 sd_notify()로 알림 | systemd-aware 앱 |
oneshot |
단발성 실행, 종료 후 active 유지 | 초기화 스크립트 |
dbus |
D-Bus 버스 이름 획득 시 준비 완료 | D-Bus 서비스 |
— — —
2. 기본 제어 명령
실습 전 디렉토리와 예제 파일을 먼저 준비합니다.
bash# 실습 디렉토리 준비 mkdir -p /tmp/linux/part2/exam_4 && cd /tmp/linux/part2/exam_4 # 실습용 애플리케이션 스크립트 생성 cat > /tmp/linux/part2/exam_4/myapp.sh << 'EOF' #!/bin/bash echo "MyApp PID: $$" while true; do echo "$(date): running" >> /tmp/linux/part2/exam_4/app.log sleep 5 done EOF chmod +x /tmp/linux/part2/exam_4/myapp.sh
이제 실습을 진행합니다.
bash# 서비스 상태 확인 (가장 자주 쓰는 명령) systemctl status nginx # 시작 / 중지 / 재시작 / 재로드 systemctl start nginx systemctl stop nginx systemctl restart nginx systemctl reload nginx # 설정만 재로드 (무중단) # 부팅 시 자동 시작 설정 systemctl enable nginx systemctl disable nginx # 활성화 + 즉시 시작 (가장 편한 방법) systemctl enable --now nginx # 서비스 완전히 멈추고 재시작 금지 (마스킹) systemctl mask nginx systemctl unmask nginx
bashsystemctl status nginx
bash# 실행 중인 모든 서비스 목록 systemctl list-units --type=service # 모든 유닛 (실패 포함) systemctl list-units --type=service --all # 실패한 서비스만 systemctl --failed # 부팅 시 활성화된 서비스 목록 systemctl list-unit-files --type=service --state=enabled # 특정 서비스의 의존성 트리 확인 systemctl list-dependencies nginx # 역방향: 이 서비스에 의존하는 유닛 systemctl list-dependencies --reverse nginx # unit 파일 내용 바로 확인 (편집기 없이) systemctl cat nginx
출력 예시:
UNIT LOAD ACTIVE SUB DESCRIPTION nginx.service loaded active running A high performance web server postgresql.service loaded active running PostgreSQL RDBMS myapp.service loaded failed failed My Application Service
LOAD 컬럼이 not-found이면 unit 파일이 없는 것입니다. ACTIVE가 failed이면 journalctl -u 서비스명 -n 50으로 원인을 확인하세요.
bashsystemctl list-units --type=service
— — —
3. 로그 조회 (journalctl)
bash# 특정 서비스 전체 로그 journalctl -u nginx # 실시간 로그 스트리밍 (tail -f와 동일) journalctl -u nginx -f # 최근 50줄 journalctl -u nginx -n 50 # 오늘 로그만 journalctl -u nginx --since today # 특정 시간대 journalctl -u nginx --since "2026-03-25 10:00" --until "2026-03-25 12:00" # 에러 레벨 이상만 (0=emerg ~ 7=debug) journalctl -u nginx -p err # JSON 출력 (로그 파이프라인에 유용) journalctl -u nginx -o json-pretty | head -30 # 부팅 이후 로그만 journalctl -u nginx -b # 이전 부팅 로그 (-1 = 직전 부팅) journalctl -u nginx -b -1
bashjournalctl -u nginx -f
— — —
4. 나만의 서비스 Unit 파일 작성
bash# 1. Unit 파일 작성 sudo vim /etc/systemd/system/myapp.service
ini[Unit] Description=My Application Server Documentation=https://github.com/myorg/myapp After=network-online.target Wants=network-online.target [Service] Type=simple User=myapp Group=myapp WorkingDirectory=/opt/myapp ExecStart=/opt/myapp/bin/server --port 8080 ExecReload=/bin/kill -HUP $MAINPID Restart=on-failure RestartSec=5 StartLimitIntervalSec=60 StartLimitBurst=3 # 환경 변수 Environment=NODE_ENV=production EnvironmentFile=-/etc/myapp/env # 앞의 -는 파일 없어도 오류 안 냄 # 표준 출력/에러를 journald로 StandardOutput=journal StandardError=journal SyslogIdentifier=myapp [Install] WantedBy=multi-user.target
bash# 2. systemd에 변경사항 반영 (파일 수정 후 항상 실행) sudo systemctl daemon-reload # 3. 서비스 시작 및 활성화 sudo systemctl enable --now myapp # 4. 동작 확인 systemctl status myapp journalctl -u myapp -f
StartLimitBurst=3 + StartLimitIntervalSec=60: 60초 안에 3번 재시작 실패하면 더 이상 재시작하지 않습니다. 무한 재시작 루프를 방지하는 중요한 설정입니다.
bashsudo systemctl daemon-reload
— — —
5. Drop-in Override 파일

패키지 관리자가 설치한 unit 파일(/lib/systemd/system/)을 직접 수정하면 패키지 업데이트 시 덮어써집니다. Drop-in override를 사용하면 원본을 건드리지 않고 특정 설정만 재정의할 수 있습니다.
bash# 권장 방법: systemctl edit (자동으로 경로 생성) sudo systemctl edit nginx # 직접 생성하는 방법 sudo mkdir -p /etc/systemd/system/nginx.service.d/ sudo vim /etc/systemd/system/nginx.service.d/override.conf
override 파일 예시 — nginx에 메모리 제한과 재시작 정책 추가:
ini[Service] # 기존 값을 초기화하려면 빈 값으로 먼저 선언 후 재정의 Restart= Restart=always RestartSec=3 # 리소스 제한 추가 MemoryMax=512M CPUQuota=50%
bash# 변경 적용 sudo systemctl daemon-reload sudo systemctl restart nginx # override 파일 확인 (원본 + override 합쳐진 결과) systemctl cat nginx
systemctl cat은 적용된 모든 설정을 파일 출처와 함께 보여줍니다. 설정이 어디서 왔는지 추적할 때 필수입니다.
— — —
6. 리소스 제한과 서비스 하드닝

컨테이너 없이 일반 systemd 서비스로 운영하던 API 서버가 취약점을 통해 침해되면, 프로세스는 루트 권한으로 파일 시스템 전체를 읽고 쓸 수 있는 상태가 됩니다. /etc/passwd, SSH 키, 데이터베이스 설정 파일까지 노출됩니다. systemd unit 파일에 보안 설정 몇 줄만 추가했더라면, 서비스가 접근 가능한 경로와 권한이 처음부터 제한되어 피해 범위를 크게 줄일 수 있었습니다. Docker나 Kubernetes 없이도 커널의 네임스페이스와 capability 제한 기능을 systemd가 직접 활성화해줍니다.
systemd는 Linux 커널의 보안 기능을 unit 파일에서 직접 활성화할 수 있습니다. 컨테이너 없이도 서비스 격리가 가능합니다.
실제 프로덕션 unit 파일 — 웹 API 서버:
ini[Unit] Description=Production API Server After=network-online.target postgresql.service Requires=postgresql.service [Service] Type=notify User=apiserver Group=apiserver WorkingDirectory=/opt/apiserver ExecStart=/opt/apiserver/bin/api-server ExecReload=/bin/kill -USR1 $MAINPID Restart=on-failure RestartSec=5 TimeoutStartSec=30 TimeoutStopSec=30 # 환경 변수 (시크릿은 별도 파일로) EnvironmentFile=/etc/apiserver/secrets.env # ── 리소스 제한 ────────────────────────────── # CPU: 최대 2코어 분량 CPUQuota=200% # 메모리: 소프트 한도 512M, 하드 한도 768M MemoryHigh=512M MemoryMax=768M # 오픈 파일 디스크립터 한도 LimitNOFILE=65536 # 프로세스 수 제한 LimitNPROC=512 # 파일 크기 제한 (코어 덤프 방지) LimitCORE=0 # ── 보안 하드닝 ────────────────────────────── # setuid/setgid 비트 실행 금지 NoNewPrivileges=yes # /usr, /boot, /etc를 읽기 전용으로 ProtectSystem=strict # /home, /root 접근 차단 ProtectHome=yes # 서비스 전용 /tmp (다른 서비스와 격리) PrivateTmp=yes # /dev 접근 최소화 PrivateDevices=yes # 커널 튜닝 파라미터 변경 금지 ProtectKernelTunables=yes # 커널 모듈 로드 금지 ProtectKernelModules=yes # 시스템 콜 필터 (화이트리스트 방식) SystemCallArchitectures=native # 쓰기 가능한 경로 명시적 허용 ReadWritePaths=/var/lib/apiserver /var/log/apiserver [Install] WantedBy=multi-user.target
각 하드닝 디렉티브의 효과:
각 설정이 어떤 공격 경로를 차단하는지 알면, 서비스 특성에 맞게 취사선택할 수 있습니다.
| 디렉티브 | 차단하는 공격 |
|---|---|
NoNewPrivileges=yes |
SUID 바이너리를 통한 권한 상승 |
ProtectSystem=strict |
시스템 파일 변조 |
PrivateTmp=yes |
/tmp를 통한 다른 서비스 공격 |
ProtectHome=yes |
홈 디렉토리 내 시크릿 파일 접근 |
PrivateDevices=yes |
원시 디바이스 파일 접근 |
ProtectKernelTunables=yes |
/proc/sys 변조 |
bash# 서비스 보안 점수 분석 (0에 가까울수록 격리 강함) systemd-analyze security myapp # 출력 예시: # NAME DESCRIPTION EXPOSURE # ✗ RootDirectory=/RootImage= Service runs within the host's root directory 0.1 # ✓ NoNewPrivileges= Service processes cannot acquire new privileges 0.0 # ✓ PrivateTmp= Service has access to private /tmp 0.0 # ... # → Overall exposure level for myapp.service: 4.2 MEDIUM # unit 파일 문법 검증 (배포 전 항상 실행) systemd-analyze verify /etc/systemd/system/myapp.service # 서비스에 실제 적용된 리소스 제한 확인 systemctl show myapp | grep -E 'Memory|CPU|Limit'
bashsystemd-analyze security myapp
— — —
7. systemd Timer (cron 대체)
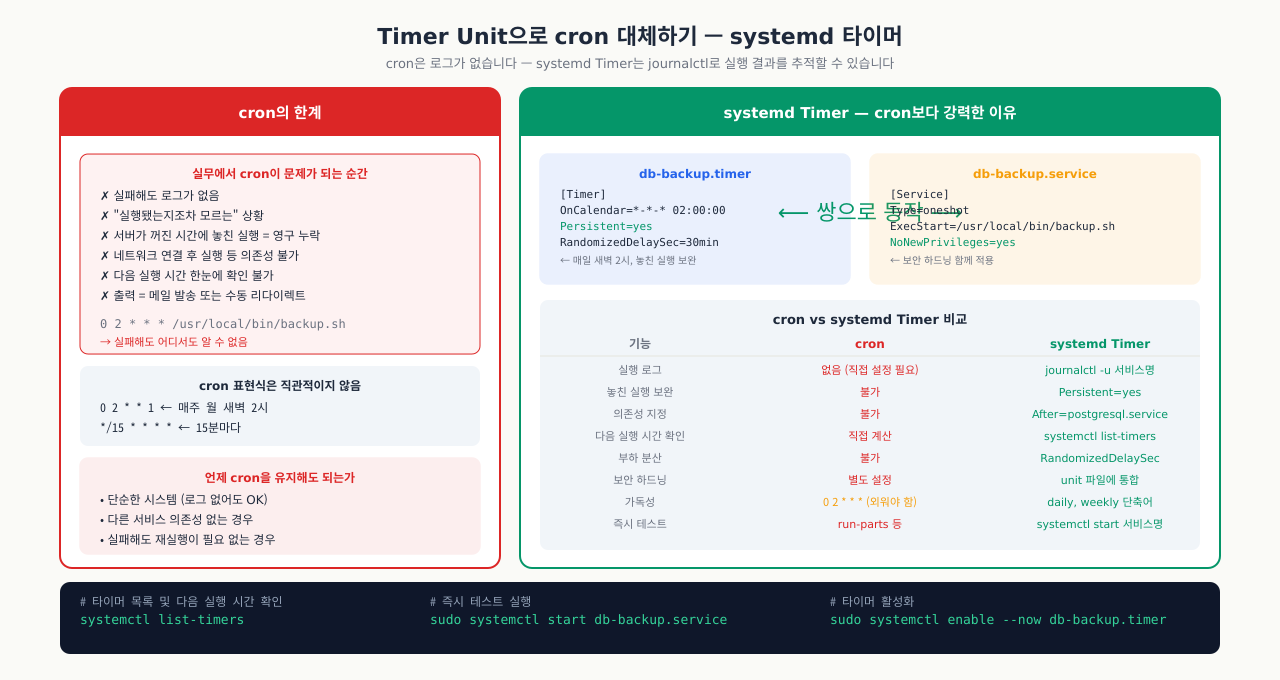
cron으로 등록한 배치 작업이 실패했는데 로그를 찾을 수 없어서, "실행이 됐는지조차 모르는" 상황이 있습니다. cron은 출력을 메일로 보내거나 직접 파일에 리다이렉트하지 않으면 로그가 없습니다. systemd Timer는 일반 서비스처럼 journalctl로 실행 로그를 볼 수 있고, 놓친 실행 보완(Persistent=yes), 의존성 지정, 다음 실행 시간 조회(systemctl list-timers) 등 cron에 없는 기능을 제공합니다. 기존 cron 작업을 Timer로 전환하면 운영 가시성이 크게 높아집니다.
cron 대비 systemd Timer의 장점:
journalctl로 실행 로그 통합 관리- 의존성 지정 가능 (네트워크 연결 후 실행 등)
- 놓친 실행 보완 (
Persistent=yes) systemctl list-timers로 다음 실행 시간 한눈에 확인
Timer unit은 항상 동명의 .service unit과 쌍으로 동작합니다.
OnCalendar 문법:
OnCalendar=는 cron 표현식과 유사하지만 더 읽기 쉬운 형식을 씁니다. 단축어(daily, weekly)로도 쓸 수 있고, 날짜/시각을 정밀하게 지정할 수도 있습니다.
*-*-* HH:MM:SS 매일 특정 시각 Mon-Fri *-*-* 09:00 평일 오전 9시 *-*-1 00:00 매월 1일 자정 weekly 매주 월요일 자정 (단축어) daily 매일 자정 (단축어) hourly 매시간 정각 (단축어)
모노토닉 타이머 (상대 시간):
OnCalendar 대신 모노토닉 타이머를 쓰면 절대 시각 대신 "부팅 후" 또는 "마지막 실행 후" 기준으로 간격을 지정할 수 있습니다.
iniOnBootSec=15min # 부팅 후 15분 OnUnitActiveSec=1h # 마지막 실행 후 1시간 OnActiveSec=10min # 타이머 활성화 후 10분
백업 작업을 매일 새벽 2시에 실행하는 타이머 예제입니다.
1단계: 서비스 유닛 작성
bashsudo vim /etc/systemd/system/db-backup.service
ini[Unit] Description=PostgreSQL Daily Backup After=postgresql.service Requires=postgresql.service # Timer에서 실행될 때는 [Install] 섹션 불필요 [Service] Type=oneshot User=backup Group=backup # 백업 스크립트 실행 ExecStart=/usr/local/bin/db-backup.sh # 보안 하드닝 NoNewPrivileges=yes PrivateTmp=yes ProtectSystem=strict ReadWritePaths=/var/backups/postgresql # 실패 시 알림 (선택) OnFailure=notify-admin@.service
2단계: 타이머 유닛 작성
bashsudo vim /etc/systemd/system/db-backup.timer
ini[Unit] Description=Daily PostgreSQL Backup Timer Requires=db-backup.service [Timer] # 매일 새벽 2시 실행 OnCalendar=*-*-* 02:00:00 # 서버가 꺼진 동안 놓친 실행을 부팅 후 즉시 보완 Persistent=yes # 정확히 2시가 아닌 ±30분 내 랜덤 지연 (서버 부하 분산) RandomizedDelaySec=30min # 함께 시작할 서비스 명시 Unit=db-backup.service [Install] WantedBy=timers.target
3단계: 활성화 및 확인
bash# 타이머 활성화 (.service가 아닌 .timer를 enable) sudo systemctl daemon-reload sudo systemctl enable --now db-backup.timer # 모든 타이머 목록 및 다음 실행 시간 확인 systemctl list-timers # 출력 예시: # NEXT LEFT LAST PASSED UNIT # Thu 2026-03-27 02:00:00 KST 9h left Wed 2026-03-26 02:00:12 KST 13h ago db-backup.timer # 타이머 대기하지 않고 즉시 테스트 실행 sudo systemctl start db-backup.service # 실행 로그 확인 journalctl -u db-backup.service -n 30
Persistent=yes 없이는 서버가 새벽 2시에 꺼져 있었다면 그날 백업이 영구 누락됩니다. 백업 타이머에서는 항상 설정하세요.
bashsystemctl list-timers
— — —
8. 부팅 시간 분석 (systemd-analyze)
bash# 총 부팅 시간 요약 systemd-analyze # 출력 예시: # Startup finished in 1.842s (kernel) + 3.291s (initrd) + 8.103s (userspace) = 13.237s # graphical.target reached after 7.812s in userspace # 각 서비스별 시작 소요 시간 (느린 순) systemd-analyze blame # 출력 예시: # 3.201s postgresql.service # 1.893s cloud-init.service # 1.241s NetworkManager-wait-online.service # 892ms snapd.service # ... # 직렬 의존성 체인 (실제 병목 구간) systemd-analyze critical-chain # 특정 서비스까지의 체인 systemd-analyze critical-chain nginx.service # SVG 타임라인 차트 생성 (브라우저로 열기) systemd-analyze plot > /tmp/boot-timeline.svg # unit 파일 검증 (문법 오류 탐지) systemd-analyze verify /etc/systemd/system/myapp.service # 보안 점수 (앞서 소개) systemd-analyze security myapp.service
critical-chain은 총 부팅 시간에 직접 영향을 주는 의존성 체인만 보여줍니다. blame에서 느린 서비스를 발견해도 critical-chain에 없으면 병렬 실행 중이라 실제 병목이 아닐 수 있습니다.
bashsystemd-analyze blame
— — —
9. 소켓 활성화 (Socket Activation)

평소에는 거의 사용되지 않는 백오피스 API나 내부 관리 툴을 항상 메모리에 올려둘 필요가 없을 때가 있습니다. 소켓 활성화는 서비스를 항상 켜두는 대신, 첫 번째 연결이 들어올 때 systemd가 자동으로 서비스를 시작하는 방식입니다. 부팅 시간을 단축할 수 있고, 서비스 재시작 중에도 소켓이 연결을 큐잉해서 요청을 잃지 않는 장점도 있습니다. Docker Desktop, DBus, SSH를 포함한 많은 시스템 서비스가 이 방식으로 동작합니다.
소켓 활성화는 서비스를 항상 실행하는 대신, 소켓에 첫 연결이 들어올 때 systemd가 서비스를 자동으로 깨우는 방식입니다.
클라이언트 요청 → 소켓 (.socket 유닛이 리스닝) → 서비스 자동 시작 → 처리
장점:
- 메모리 절약 (유휴 상태에서 서비스 미실행)
- 부팅 시간 단축 (필요할 때 지연 시작)
- 서비스 재시작 중에도 연결 큐잉 (무중단)
ini# myapp.socket [Unit] Description=My App Socket [Socket] ListenStream=8080 Accept=no [Install] WantedBy=sockets.target
ini# myapp.service — [Install] 섹션 없음 (소켓이 활성화하므로) [Unit] Description=My App Service [Service] ExecStart=/opt/myapp/bin/server StandardInput=socket
bash# 소켓만 활성화 (서비스는 연결 시 자동 시작) sudo systemctl enable --now myapp.socket
SSH, DBus, 많은 시스템 서비스가 이 방식으로 동작합니다.
— — —
10. journald 로그 보존 설정

디스크 사용률 경보가 울려 확인해보면 /var/log/journal이 수십 GB를 차지하고 있는 경우가 있습니다. 설정을 하지 않은 journald는 가용 디스크의 10%까지 로그를 계속 쌓고, 어느 날 갑자기 서비스가 로그를 쓰지 못해 오동작하거나 디스크 풀로 SSH 접속조차 안 되는 상황이 생깁니다. 로그 보존 정책은 서비스 초기 세팅 시 빠트리기 쉬운 항목이지만, 미리 한도를 잡아두면 이런 상황을 완전히 막을 수 있습니다.
기본 설정으로는 디스크가 가득 찰 때까지 로그가 쌓입니다. 프로덕션 서버에서는 명시적으로 한도를 설정해야 합니다.
bashsudo vim /etc/systemd/journald.conf
ini[Journal] # 저장 방식: persistent(디스크), volatile(메모리), auto(기본) Storage=persistent # 최대 디스크 사용량 (전체 로그) SystemMaxUse=2G # 파일 하나의 최대 크기 SystemMaxFileSize=200M # 보존 기간 (오래된 로그 자동 삭제) MaxRetentionSec=30day # 압축 여부 Compress=yes # Rate limiting: 30초에 서비스당 최대 10000 메시지 RateLimitIntervalSec=30s RateLimitBurst=10000
bash# 설정 적용 sudo systemctl restart systemd-journald # 현재 로그 디스크 사용량 확인 journalctl --disk-usage # 수동으로 오래된 로그 삭제 sudo journalctl --vacuum-size=1G # 1G 이하로 줄이기 sudo journalctl --vacuum-time=14d # 14일 이상 된 로그 삭제 # 특정 부팅 ID 목록 journalctl --list-boots
로그 수집 스택(ELK, Loki 등)을 운영한다면 MaxRetentionSec을 짧게 유지해도 됩니다. 로컬 로그는 장애 초기 대응용으로만 사용하기 때문입니다.
— — —
11. 실패 디버깅
원인: Type=simple로 설정된 서비스에서 fork 후 부모 프로세스가 바로 종료되는 경우. systemd는 원래 PID를 추적하므로 자식 프로세스가 죽어도 active 상태를 유지합니다.
확인:
bashsystemctl status myapp # 상태는 active(running)이지만 실제 동작 없음 # 실제 프로세스 확인 ps aux | grep myapp # PID 추적 systemctl show myapp --property=MainPID
해결:
ini[Service] # fork하는 데몬의 경우 Type=forking PIDFile=/var/run/myapp.pid # 또는 앱이 sd_notify를 지원하면 Type=notify # 헬스체크로 실제 상태 보장 ExecStartPost=/usr/bin/curl -sf http://localhost:8080/health
흔한 원인 3가지:
- 환경 변수 없음: systemd 서비스는
/etc/environment와~/.bashrc를 읽지 않음 - 현재 디렉토리 없음:
WorkingDirectory지정 필요 - 권한 문제:
User=지정한 사용자가 실행 파일이나 로그 경로에 접근 불가
디버깅 순서:
bash# 1. 상세 에러 확인 journalctl -u myapp.service -n 50 --no-pager # 2. 해당 사용자로 직접 실행 테스트 sudo -u myapp /opt/myapp/bin/server # 3. 적용된 환경 변수 확인 systemctl show myapp | grep -E 'Exec|Environment|WorkingDir' # 4. unit 파일 문법 검증 systemd-analyze verify /etc/systemd/system/myapp.service # 5. SELinux/AppArmor 거부 여부 ausearch -m avc -ts recent | grep myapp # 또는 journalctl -k | grep apparmor
증상: systemctl list-timers에 나타나지만 LAST 실행이 없거나, 예상 시각에 실행되지 않음.
확인 체크리스트:
bash# 1. 타이머 유닛 상태 확인 (.service가 아닌 .timer!) systemctl status db-backup.timer # 2. 연결된 서비스 유닛 상태 systemctl status db-backup.service # 3. OnCalendar 문법 검증 systemd-analyze calendar "*-*-* 02:00:00" # 출력: # Original form: *-*-* 02:00:00 # Normalized form: *-*-* 02:00:00 # Next elapse: Thu 2026-03-27 02:00:00 KST # (in UTC): Wed 2026-03-26 17:00:00 UTC # 4. 서비스 직접 실행으로 스크립트 오류 확인 sudo systemctl start db-backup.service journalctl -u db-backup.service -n 20 # 5. Persistent=yes 설정 여부 확인 (놓친 실행 보완) systemctl cat db-backup.timer | grep Persistent
systemd-analyze calendar 명령으로 OnCalendar 문자열을 검증하면 잘못된 문법을 배포 전에 잡을 수 있습니다. 타임존도 함께 확인하세요.
증상: journalctl -u myapp에서 Memory limit exceeded 또는 Killed 메시지.
bash# 현재 메모리 사용량 확인 systemctl show myapp | grep -i memory # cgroup 레벨에서 실제 사용량 cat /sys/fs/cgroup/system.slice/myapp.service/memory.current # OOM 이벤트 커널 로그 journalctl -k | grep -i oom | tail -20 # 실시간 모니터링 systemd-cgtop
해결 접근:
ini[Service] # 1. 한도 자체를 올림 MemoryMax=1G # 2. 소프트/하드 구분하여 여유 확보 MemoryHigh=768M # 이 값 초과 시 메모리 회수 압력 MemoryMax=1G # 이 값 초과 시 OOM 킬 # 3. 스왑 사용 허용 MemorySwapMax=256M
— — —
12. 실무 맥락
실무에서 새 버전을 배포할 때 다운타임 없이 서비스를 교체하는 패턴입니다.
bash# 1. 새 바이너리 배치 cp /tmp/myapp-v2 /opt/myapp/bin/server.new chmod +x /opt/myapp/bin/server.new chown myapp:myapp /opt/myapp/bin/server.new # 2. unit 파일 변경이 있으면 반드시 reload sudo systemctl daemon-reload # 3. 설정에 ExecReload가 있으면 reload (SIGHUP으로 graceful reload) systemctl reload myapp 2>/dev/null || systemctl restart myapp # 4. 배포 후 헬스체크 (실패 시 롤백) for i in 1 2 3 4 5; do sleep 2 if curl -sf http://localhost:8080/health; then echo "배포 성공" exit 0 fi done # 5. 헬스체크 실패 시 롤백 echo "헬스체크 실패, 롤백 시작" cp /opt/myapp/bin/server.bak /opt/myapp/bin/server systemctl restart myapp exit 1
핵심: Restart=on-failure + RestartSec=3 조합으로 크래시 자동 복구. StartLimitBurst=3으로 무한 재시작 루프 방지. Drop-in override로 환경별 설정 분리 (개발/스테이징/프로덕션).
팀에서 crontab으로 관리하던 작업들이 분산되어 추적이 어려운 상황에서 systemd Timer로 일원화하는 과정입니다.
bash# 현재 cron 목록 파악 crontab -l sudo crontab -l cat /etc/cron.d/* # 예시 cron 항목: # 0 2 * * * /usr/local/bin/db-backup.sh >> /var/log/backup.log 2>&1 # 마이그레이션 후 검증 systemctl list-timers --all # cron과 timer 동시 실행 방지: cron 항목 주석 처리 후 # timer가 안정적으로 실행됨을 1주일 확인 후 cron 삭제
마이그레이션 이점:
- 로그가
journalctl -u db-backup으로 중앙 집중 - 실행 실패 시
OnFailure=디렉티브로 알림 자동화 systemctl list-timers로 다음 실행 시간 즉시 확인- 서비스에 리소스 제한과 보안 하드닝 적용 가능
주의: Persistent=yes를 설정하지 않으면 서버가 실행 시각에 꺼져 있던 경우 그 실행은 영구 누락됩니다. 백업, 정산 같은 중요 작업에는 반드시 설정하세요.
— — —
다음 모듈에서는 텍스트 처리(Text Processing)를 다룹니다 — grep, awk, sed, sort, uniq로 로그를 분석하고 파이프라인을 구성하는 방법을 배웁니다.
'Linux' 카테고리의 다른 글
| [Linux] Bash 스크립팅 기초 (0) | 2026.05.22 |
|---|---|
| [Linux] 텍스트 처리 (grep/awk/sed) (0) | 2026.05.22 |
| [Linux ] 시그널 & 프로세스 종료 (0) | 2026.05.22 |
| [Linux] 프로세스 관리 (Process Management) (0) | 2026.05.22 |
| [Linux] 환경변수 & dotfiles (0) | 2026.05.22 |