새벽 2시, 서버 CPU가 98%를 찍고 알람이 울렸습니다. SSH로 접속은 됐는데 응답이 느립니다. 어떤 프로세스가 원인인지, 어떻게 종료하는지, 종료했는데 왜 다시 살아나는지 — 모르면 30분이 지나도 원인을 못 찾습니다.
이 모듈을 마치면 ps, top, kill, strace로 프로덕션 서버의 프로세스를 추적하고, 안전하게 종료하고, 좀비·고아 프로세스를 정리하는 전체 흐름을 혼자 할 수 있습니다.
프로세스 관리 (Process Management)
ps aux | wc -l
pstree -p | head -20
ps aux | awk '$8 ~ /Z/'
ps aux --sort=-%cpu | head -10
모든 프로세스는 부모-자식 관계로 연결된 트리 구조를 형성합니다. PID 1(systemd 또는 init)이 최상위 조상이며, 모든 프로세스는 이 트리에서 어딘가에 위치합니다.
PID 1 (systemd/init) ├── PID 234 (sshd) │ └── PID 891 (sshd: user session) │ └── PID 892 (bash) │ └── PID 1042 (vim) └── PID 456 (nginx) ├── PID 457 (nginx worker) └── PID 458 (nginx worker)
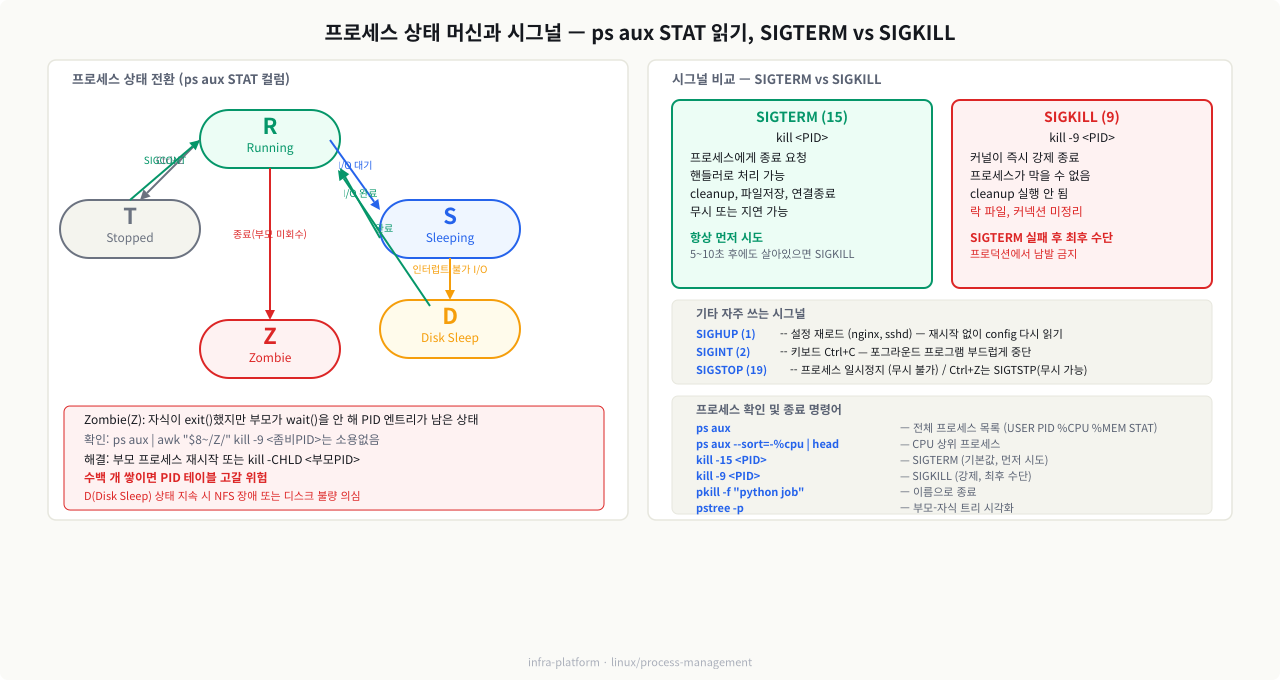
프로세스 상태 코드 — ps aux의 STAT 컬럼에 나타남:
상태코드의미주의 포인트RunningRCPU에서 실행 중 또는 실행 대기여러 개면 정상, 한 개가 100% 점유하면 문제SleepingSI/O 대기 (인터럽트 가능)대부분의 프로세스가 이 상태Disk SleepDI/O 대기 (인터럽트 불가)NFS 행, 디스크 불량 의심StoppedT정지됨 (Ctrl+Z 또는 SIGSTOP)개발 중 일시정지ZombieZ종료됐지만 부모가 회수 안 함수백 개 쌓이면 PID 테이블 고갈 위험
STAT 코드 뒤에 붙는 수식어도 중요합니다: s는 세션 리더, +는 포어그라운드 프로세스, l은 멀티스레드, <는 높은 우선순위, N은 낮은 우선순위(nice 적용)를 의미합니다.
시그널은 프로세스 간 또는 커널이 프로세스에게 보내는 비동기 알림입니다. kill 명령의 이름은 "종료"지만 실제로는 "시그널 전송"이 더 정확한 표현입니다.
실무에서 자주 쓰는 시그널:
시그널번호기본 동작언제 쓰는가SIGTERM15프로세스에게 정상 종료 요청항상 먼저 시도. 프로세스가 cleanup 로직을 실행할 기회를 줌SIGKILL9커널이 즉시 강제 종료SIGTERM 이후 5~10초 기다려도 안 죽을 때만 사용SIGHUP1원래 의미: 터미널 끊김. 현재 관례: 설정 재로드nginx, sshd 등 데몬 설정을 재시작 없이 다시 읽힐 때SIGINT2키보드 인터럽트 (Ctrl+C와 동일)터미널 프로그램을 부드럽게 중단할 때SIGSTOP19프로세스 일시 정지 (무시 불가)디버깅 중 프로세스 상태 고정SIGCONT18SIGSTOP 이후 재개SIGSTOP으로 멈춘 프로세스 재개SIGCHLD17자식 프로세스 상태 변경 알림Zombie 문제 해결 시 부모에게 전송SIGUSR1/210/12사용자 정의애플리케이션마다 의미가 다름 (로그 로테이션 등)
핵심 규칙: SIGKILL은 커널이 직접 프로세스를 제거하므로 프로세스가 가로챌 수 없습니다. 반면 SIGTERM은 프로세스가 핸들러를 등록해서 무시하거나 지연 처리할 수 있습니다. 프로덕션에서 kill -9를 남발하면 데이터 유실, 락 파일 미정리, 커넥션 비정상 종료 같은 부작용이 생깁니다.
SIGHUP 실무 예시:
bash# nginx 설정 변경 후 재시작 없이 적용 nginx -t && kill -HUP $(cat /var/run/nginx.pid) # sshd 설정 재로드 kill -HUP $(pgrep sshd)
기본 실습
실습 전 디렉토리와 예제 파일을 먼저 준비합니다.
bash# 실습 디렉토리 준비 mkdir -p /tmp/linux/part2/exam_2 && cd /tmp/linux/part2/exam_2 # 백그라운드 실습용 장시간 실행 스크립트 생성 cat > /tmp/linux/part2/exam_2/long_task.sh << 'EOF' #!/bin/bash # 백그라운드 실습용 장시간 실행 스크립트 count=0 while true; do count=$((count + 1)) echo "$(date): iteration $count" >> /tmp/linux/part2/exam_2/task.log sleep 2 done EOF chmod +x /tmp/linux/part2/exam_2/long_task.sh
이제 실습을 진행합니다.
ps aux는 현재 시스템의 모든 프로세스 스냅샷을 출력합니다. top과 달리 실시간 갱신이 없어 스크립트에 쓰기 좋습니다.
bash# 모든 프로세스 출력 ps aux # CPU 사용량 높은 순서로 정렬 ps aux --sort=-%cpu | head -10 # 메모리 사용량 높은 순서로 정렬 ps aux --sort=-%mem | head -10 # 특정 프로세스 이름으로 검색 ps aux | grep nginx # 프로세스 트리 형태로 보기 (--forest) ps auxf
출력 컬럼 의미: USER 실행 사용자, PID 프로세스 ID, %CPU CPU 점유율, %MEM 메모리 점유율, VSZ 가상 메모리(KB), RSS 실제 물리 메모리(KB), STAT 상태, START 시작 시간, COMMAND 실행 명령어.
top은 CPU/메모리 사용량을 실시간으로 보여줍니다. 프로덕션 서버 알람을 받고 ssh 접속 직후 가장 먼저 실행하는 명령입니다.
bash# 기본 실행 top # 특정 사용자의 프로세스만 top -u www-data # 업데이트 간격 1초로 설정하고 10회 후 종료 (스크립트용) top -bn10 -d1 | grep "Cpu\|Mem"
top 내 단축키 (실행 중 누르기):
P: CPU 사용량 기준 정렬M: 메모리 사용량 기준 정렬k: 프로세스 종료 (PID 입력 후 시그널 번호 입력)r: nice 값 변경 (renice)1: CPU 코어별 사용량 토글H: 스레드 레벨로 표시 토글q: 종료
htop이 설치된 서버라면 더 직관적인 UI를 제공합니다. 화살표 키로 프로세스 선택, F9로 시그널 전송, F6로 정렬 기준 변경이 가능합니다.
pstree는 프로세스 계층 구조를 트리 형태로 보여줍니다. 어떤 프로세스가 어디서 spawned됐는지 파악할 때 ps auxf보다 읽기 좋습니다.
bash# PID 포함 전체 트리 pstree -p # 특정 프로세스 기준으로 트리 보기 pstree -p $(pgrep nginx | head -1) # 특정 사용자의 프로세스 트리 pstree -pu www-data # 스레드도 포함해서 보기 pstree -pt
실무 활용: 장애 대응 시 "이 프로세스가 왜 이렇게 많이 떠 있지?"라는 질문에 답하려면 부모 프로세스를 추적해야 합니다. pstree가 그 시작점입니다. 예를 들어 PHP-FPM 워커가 수백 개 뜬 상황에서 부모 프로세스의 설정을 확인하는 식으로 사용합니다.
bash# 정상 종료 요청 (항상 먼저 시도) kill 1234 kill -15 1234 kill -SIGTERM 1234 # 셋 다 동일 # 5초 기다린 후 살아있으면 강제 종료 kill -SIGTERM 1234 && sleep 5 && kill -SIGKILL 1234 2>/dev/null # 이름으로 모든 같은 이름 프로세스 종료 killall nginx # 패턴으로 종료 (프로세스 이름 전체가 아닌 일부 매칭) pkill -f "python manage.py" # SIGHUP으로 설정 재로드 (재시작 없이) kill -HUP $(pgrep -o nginx) # 시그널 전송 전 대상 프로세스 확인 (dry-run 역할) pgrep -a -f "gunicorn"
안전한 종료 스크립트 패턴:
bashPID=$(pgrep -f "myapp") if [ -n "$PID" ]; then kill -SIGTERM $PID # 최대 10초 대기 for i in $(seq 1 10); do kill -0 $PID 2>/dev/null || break sleep 1 done # 아직 살아있으면 강제 종료 kill -0 $PID 2>/dev/null && kill -SIGKILL $PID fi
SSH 세션이 끊기면 해당 세션의 모든 자식 프로세스에게 SIGHUP이 전달됩니다. 이를 막는 방법이 두 가지 있습니다.
bash# nohup: SIGHUP을 무시하고 실행, 출력은 nohup.out으로 nohup python3 long_job.py > /var/log/job.log 2>&1 & # 실행 중인 프로세스를 shell에서 분리 (이미 실행한 경우) ./long_job.sh & disown %1 # 마지막 백그라운드 작업 분리 disown -a # 모든 백그라운드 작업 분리 # disown 후 확인 (jobs 목록에서 사라져야 함) jobs # 더 나은 방법: tmux나 screen 사용 tmux new-session -d -s myjob 'python3 long_job.py' tmux attach -t myjob
nohup vs disown 차이: nohup은 처음부터 SIGHUP을 무시한 상태로 프로세스를 시작합니다. disown은 이미 실행 중인 프로세스를 shell의 job 테이블에서 제거해서 shell이 종료될 때 시그널을 안 보내게 만듭니다. 장기 배치 작업이라면 tmux/screen이 훨씬 관리하기 편합니다.
Linux 스케줄러는 nice 값(-20에서 19)으로 CPU 우선순위를 결정합니다. 낮을수록 우선순위가 높고, 높을수록 낮습니다(역직관적이지만 "남에게 양보하는 정도"라고 기억하세요).
bash# nice 값 10으로 백업 실행 (낮은 우선순위 = 다른 작업 방해 최소화) nice -n 10 tar -czf backup.tar.gz /var/data # 실행 중인 프로세스의 nice 값 변경 renice -n 15 -p 1234 # 특정 사용자의 모든 프로세스 우선순위 낮추기 renice -n 10 -u batchuser # 현재 nice 값 확인 ps -o pid,ni,comm -p 1234 # nice 값 -5 (높은 우선순위, root만 가능) sudo nice -n -5 ./critical_task.sh
실무 시나리오: 주간에 대용량 파일 압축이나 DB 덤프를 해야 할 때 nice -n 19로 실행하면 서비스에 영향을 주지 않고 백그라운드에서 돌릴 수 있습니다. 반대로 특정 프로세스에 더 많은 CPU를 주고 싶으면 (root 권한으로) nice 값을 음수로 줄입니다.
strace는 프로세스가 커널에 요청하는 시스템 콜을 실시간으로 보여줍니다. "이 프로세스가 왜 CPU를 많이 쓰는 거야?", "어느 파일을 열고 있어?", "왜 hang이 걸렸어?"라는 질문에 직접적인 답을 줍니다.
bash# 새 프로세스를 strace로 실행 strace ls /tmp # 실행 중인 프로세스 attach strace -p 1234 # 시스템 콜 통계 (어떤 콜이 많이 호출됐는지) strace -c ls /tmp # 특정 시스템 콜만 필터링 (파일 관련만) strace -e trace=open,openat,read,write,close ls /tmp # 타임스탬프 포함 strace -t -p 1234 # 자식 프로세스도 추적 strace -f -p 1234 # 출력을 파일로 저장 (긴 세션용) strace -o /tmp/strace_output.txt -p 1234
strace 읽는 법:
openat(AT_FDCWD, "/etc/passwd", O_RDONLY) = 3 read(3, "root:x:0:0:root:/root:/bin/bash\n", 4096) = 32 close(3) = 0
시스템콜(인자) = 반환값 형식입니다. 반환값이 -1이면 에러이고 바로 뒤에 errno가 나옵니다.
주의: strace는 프로세스 성능을 크게 저하시킵니다. 프로덕션에서는 문제 재현 중에만 짧게 쓰고 바로 detach하세요.
lsof(List Open Files)는 프로세스가 열어둔 파일, 소켓, 파이프를 모두 보여줍니다. Linux에서 "모든 것이 파일"이라는 철학 덕분에 네트워크 포트도 lsof로 조회됩니다.
bash# 특정 포트를 점유한 프로세스 찾기 lsof -i :8080 lsof -i :80 -i :443 # 특정 PID의 열린 파일 전체 lsof -p 1234 # 특정 파일을 열고 있는 프로세스 찾기 lsof /var/log/app.log # 삭제됐지만 아직 열린 파일 찾기 (디스크 공간 안 돌아오는 원인) lsof | grep deleted # 특정 사용자의 열린 파일 lsof -u www-data # TCP/UDP 연결 상태 lsof -i TCP -n -P lsof -i UDP -n -P # 열린 파일 개수 (파일 디스크립터 고갈 진단) lsof -p 1234 | wc -l
lsof 출력 컬럼: COMMAND 프로세스 이름, PID, USER, FD 파일 디스크립터 번호/타입, TYPE 파일 유형(REG/DIR/IPv4/IPv6/FIFO), NODE inode 번호, NAME 파일 경로 또는 소켓 정보.
/proc는 커널이 메모리에 제공하는 가상 파일시스템입니다. 각 PID별 디렉토리에서 프로세스의 모든 정보를 읽을 수 있습니다.
bash# 프로세스 상태 요약 (메모리, 스레드 수, 시그널 마스크 등) cat /proc/1234/status # 현재 열린 파일 디스크립터 목록 (lsof보다 빠름) ls -la /proc/1234/fd # 파일 디스크립터 개수만 빠르게 ls /proc/1234/fd | wc -l # 프로세스 환경변수 확인 (실행 시점의 env) cat /proc/1234/environ | tr '\0' '\n' # 실행 파일 경로 (심볼릭 링크) readlink /proc/1234/exe # 현재 작업 디렉토리 readlink /proc/1234/cwd # 메모리 맵 (어떤 라이브러리를 로드했는지) cat /proc/1234/maps # CPU/메모리 통계 (원시 데이터) cat /proc/1234/stat cat /proc/1234/statm # 시스템 전체 통계 cat /proc/meminfo cat /proc/cpuinfo cat /proc/loadavg
실무 활용: 프로세스가 예상치 못한 설정으로 실행됐는지 의심될 때 /proc/PID/environ으로 환경변수를 직접 확인합니다. 또 파일 디스크립터 한도(ulimit -n)에 걸릴 것 같으면 /proc/PID/fd의 파일 수를 모니터링합니다.
CPU 친화성(Affinity)은 특정 프로세스가 특정 CPU 코어에서만 실행되도록 제한하는 기능입니다. NUMA 아키텍처에서 성능을 최적화하거나 실시간 작업을 격리할 때 씁니다.
bash# 0번, 1번 코어만 사용하도록 실행 taskset -c 0,1 ./myapp # 실행 중인 프로세스의 CPU 친화성 변경 taskset -cp 0,1 1234 # 현재 프로세스의 CPU 친화성 확인 taskset -cp 1234 # 16코어 서버에서 0~7번 코어만 사용 taskset -c 0-7 ./myapp # 코어 번호 대신 비트마스크로 지정 (0x3 = 코어 0,1) taskset 0x3 ./myapp
언제 쓰나: 고빈도 거래 시스템, 실시간 미디어 처리, CPU 집약적 배치 작업을 특정 코어에 격리해서 다른 서비스의 캐시를 방해하지 않게 할 때 씁니다. 일반 웹 서비스에서는 불필요하지만 SRE 면접에서 자주 나오는 개념입니다.
트러블슈팅
원인: 자식 프로세스가 종료됐지만 부모 프로세스가 wait() 시스템 콜을 호출하지 않아 프로세스 테이블 엔트리가 남아 있는 상태. 자식이 종료 코드를 전달하려고 기다리는 중입니다.
특징:
ps aux에서Z상태, COMMAND에- 실제 메모리/CPU는 거의 사용하지 않음
- PID 테이블 슬롯을 점유해서 PID가 고갈될 수 있음 (기본 PID 최대값 32768)
진단 및 해결:
bash# Zombie 프로세스 찾기 ps aux | awk '$8 ~ /Z/' # Zombie의 부모 PID 확인 ps -el | grep Z ps -o ppid= -p # 부모에게 SIGCHLD 보내서 wait() 유도 kill -SIGCHLD # 그래도 안 되면 부모 프로세스 종료 (zombie도 자동 정리됨) kill -SIGTERM # 부모가 죽으면 zombie는 PID 1(systemd)에 입양되고 즉시 회수됨 # strace로 부모가 SIGCHLD 핸들러 있는지 확인 strace -e signal -p
장기 해결: 애플리케이션 코드에서 SIGCHLD 시그널 핸들러로 waitpid(-1, WNOHANG)를 비동기 호출하거나, 멀티스레드 서버라면 pthread_join()을 제대로 호출해야 합니다.
원인: NFS/CIFS 마운트 문제, 디스크 I/O 행, 드라이버 버그 등으로 커널 I/O를 무한 대기 중. 커널 레벨에서 잠자고 있어서 어떤 시그널도 처리되지 않습니다.
왜 kill -9가 안 되는가: SIGKILL은 커널이 다음번에 해당 프로세스를 CPU에 스케줄링할 때 처리합니다. 그런데 D 상태 프로세스는 커널 I/O 경로 안에 갇혀 스케줄링 자체가 안 되므로 시그널 처리 기회가 없습니다.
진단:
bash# D 상태 프로세스 찾기 ps aux | awk '$8 == "D"' # 어떤 파일/소켓을 기다리는지 lsof -p # 커널 스택 덤프 (무엇을 기다리는지) cat /proc//wchan cat /proc//stack # root 권한 필요 # 시스템 전체 I/O 상태 iostat -x 1 5 dmesg | tail -30 # NFS 마운트가 원인인 경우 mount | grep nfs umount -f -l /mnt/nfs_share # force + lazy unmount
해결 순서:
- NFS/CIFS라면 마운트 강제 해제 시도
- 블록 디바이스 I/O 오류라면
dmesg에서 disk error 확인 - 위 모두 실패 시 재부팅이 유일한 해결책
새 서비스를 띄우려는데 포트가 점유돼 있는 상황. 가장 흔한 신입 엔지니어 당황 포인트입니다.
진단:
bash# 어떤 프로세스가 8080을 쓰는지 확인 lsof -i :8080 ss -tlnp | grep 8080 # ss가 더 빠름 # PID 확인 후 해당 프로세스 정보 조회 ps -p -o pid,ppid,user,command # 혹시 TIME_WAIT 상태 커넥션인지 확인 (이 경우 프로세스가 없을 수도 있음) ss -tnp | grep 8080
해결:
bash# 확인 후 종료 kill -SIGTERM # 자동으로 찾아서 종료하는 원라이너 lsof -t -i :8080 | xargs kill -SIGTERM # 서비스가 systemd 관리라면 systemctl stop myservice # SO_REUSEADDR가 없는 프로그램이라면 TIME_WAIT 소진까지 기다리거나 # net.ipv4.tcp_tw_reuse 커널 파라미터 조정 (주의해서 사용)
예방: 서비스 스크립트에 SO_REUSEADDR 소켓 옵션을 활성화하면 TIME_WAIT 상태 포트를 즉시 재사용할 수 있습니다.
rm으로 큰 로그 파일을 지웠는데 df -h에서 공간이 줄지 않는 상황. 파일을 열고 있는 프로세스가 살아있으면 inode가 해제되지 않습니다.
원인과 진단:
bash# 삭제됐지만 아직 열린 파일 찾기 lsof | grep deleted # 출력 예시: # nginx 1234 www-data 1w REG 8,1 4294967296 12345 /var/log/nginx/access.log (deleted) # 프로세스가 살아있어서 파일 디스크립터를 통해 여전히 파일에 접근 중 # 해당 파일 디스크립터를 /proc에서 직접 확인 ls -la /proc/1234/fd | grep 1 # fd 번호 1번
해결:
bash# 방법 1: 프로세스에 로그 재오픈 시그널 전송 (nginx의 경우 USR1) kill -USR1 $(cat /var/run/nginx.pid) # 방법 2: /proc/fd를 통해 파일 내용 비우기 (프로세스 재시작 없이) # FD 번호를 lsof에서 확인 후: > /proc/1234/fd/5 # fd 5번 파일 내용 truncate # 방법 3: 서비스 재시작 (파일 디스크립터가 닫히면서 inode 해제) systemctl restart nginx
OSError: [Errno 24] Too many open files
진단:
bash# 현재 프로세스의 열린 FD 수 ls /proc//fd | wc -l # 시스템 한도 확인 ulimit -n # 현재 세션 soft limit cat /proc//limits # 특정 프로세스의 한도 # 어떤 파일이 많이 열렸는지 분석 lsof -p | awk '{print $5}' | sort | uniq -c | sort -rn # 소켓이 많다면 연결 상태 확인 lsof -p -i | head -20
해결:
bash# 임시: 실행 중인 프로세스의 한도 늘리기 (root 필요) prlimit --nofile=65536 --pid # 영구: /etc/security/limits.conf echo "www-data soft nofile 65536" >> /etc/security/limits.conf echo "www-data hard nofile 65536" >> /etc/security/limits.conf # systemd 관리 서비스라면 [Service] 섹션에: # LimitNOFILE=65536 systemctl edit myservice
실무 맥락
새벽 2시, PagerDuty 알람이 울립니다. "API 서버 CPU 사용률 98%, 응답 지연 10초." SSH 접속 직후 다음 순서로 움직입니다.
bash# Step 1: 현황 파악 (30초 이내) top -bn1 | head -25 # 또는 더 상세하게: ps aux --sort=-%cpu | head -10 # Step 2: 범인 프로세스 특정 # CPU 1위 프로세스의 PID를 기록: 예) PID=7823 # Step 3: 프로세스 신원 확인 ps -p 7823 -o pid,ppid,user,lstart,command readlink /proc/7823/exe cat /proc/7823/cmdline | tr '\0' ' ' # Step 4: 무슨 일을 하는지 strace로 확인 (10초만) timeout 10 strace -c -p 7823 # 시스템 콜 통계에서 write()나 futex()가 압도적이면 각각 I/O 폭주, 락 경합 # Step 5: 열린 파일/소켓 확인 lsof -p 7823 | head -30 # Step 6: Java 프로세스라면 스레드 덤프 jstack 7823 > /tmp/threaddump_$(date +%Y%m%d_%H%M%S).txt # Step 7: /proc로 추가 정보 수집 cat /proc/7823/status | grep -E "Threads|VmRSS|VmPeak" cat /proc/7823/environ | tr '\0' '\n' | grep -E "JAVA|NODE|PYTHON" # Step 8: 즉시 부하 경감이 필요하면 renice -n 19 -p 7823 # CPU 우선순위 낮춰서 다른 서비스 보호 # Step 9: 종료 결정 시 (데이터 유실 방지 우선) kill -SIGTERM 7823 sleep 10 kill -0 7823 2>/dev/null && kill -SIGKILL 7823 # Step 10: 로그 확인 journalctl -u myservice --since "1 hour ago" | tail -100
핵심 원칙: 원인 모르게 kill -9부터 치면 문제 재현 기회를 잃습니다. 최소 30초는 정보 수집에 씁니다. 코어 덤프나 스레드 덤프를 떠놓으면 사후 분석이 가능합니다.
배포 스크립트를 돌렸는데 실제로 새 버전이 뜬 건지 확신이 안 설 때. 특히 무중단 배포(rolling update) 후에 흔히 하는 검증 루틴입니다.
bash# 1. 현재 실행 중인 프로세스와 실행 파일 경로 확인 ps aux | grep myapp readlink /proc//exe # 2. 프로세스 시작 시각 확인 (새로 뜬 게 맞는지) ps -p -o pid,lstart,etimes,command # lstart: 시작 절대 시각, etimes: 실행 경과 초 # 3. 환경변수로 버전/환경 확인 cat /proc//environ | tr '\0' '\n' | grep -E "VERSION|ENV|APP" # 4. 열린 파일로 어떤 config를 읽었는지 확인 lsof -p | grep -E "\.conf|\.yaml|\.env" # 5. 포트 바인딩 확인 (새 프로세스가 포트를 잡았는지) lsof -i :8080 -P -n # 6. 이전 프로세스가 아직 살아있는지 pstree로 확인 pstree -p | grep myapp # 7. /proc/PID/maps로 로드된 라이브러리 버전 확인 grep "myapp" /proc//maps
이 루틴을 배포 후 체크리스트로 만들어두면 "배포했는데 왜 이전 버전으로 요청이 가지?"라는 황당한 상황을 막을 수 있습니다. 특히 심볼릭 링크로 배포하는 레거시 환경에서 readlink /proc/PID/exe는 강력한 검증 도구입니다.


다음 모듈에서는 프로세스 시그널(Process Signals)을 더 깊이 다룹니다 — SIGTERM, SIGKILL, SIGHUP, SIGUSR1/2의 동작 차이, 시그널 핸들러 작성, 그리고 graceful shutdown 패턴을 배웁니다.
'Linux' 카테고리의 다른 글
| [Linux ] systemd 서비스 관리 (0) | 2026.05.22 |
|---|---|
| [Linux ] 시그널 & 프로세스 종료 (0) | 2026.05.22 |
| [Linux] 환경변수 & dotfiles (0) | 2026.05.22 |
| [Linux] tmux & 백그라운드 세션 관리 (0) | 2026.05.22 |
| [Linux] 패키지 관리 (apt/yum/dnf) (0) | 2026.05.22 |